Table Of Contents
How to calculate Running Totals and Sums in SQL Intermediate
REST in PostgreSQL Part 3 B - The REST Client in Adobe Flex 3 with Paging Intermediate
From the Editors
What can PostgreSQL learn from MySQL
There has been a lot of talk lately about PostgreSQL and what MySQL can learn from the PostgreSQL clan. We would like to look at the reverse of that. This article is a bit of a complement to Joshua Drake's What MySQL (and really, Sun) can learn from PostgreSQL.
First of all a lot of staunch advocates of PostgreSQL wonder what exactly is it that MySQLers see in that beast of a database or as Martin Mickos likes to call it The Ferrari of databases?
For example, as Magnus Hagander pointed out in A new MySQL gotcha and we pointed out in SQL Math Idiosyncracies, MySQL's casting behavior is shall we say odd. I won't even recount our frustrations with using their ODBC driver with the MySQL 5.0 incarnations, but that could be ignorance on our part. Zack Urlocker of Sun has espoused, the upcoming MySQL 5.1 will have no bugs so perhaps this along with other bug complaints is a moot point.
So why do people choose MySQL time and time again over PostgreSQL and why is PostgreSQL sometimes a hard sell? Some of what we are going to say is a bit tongue-in-cheek so please don't take offense.
MySQL is pervasive and ubiquitous
Being pervasive and ubiquitous is a huge selling point.
- It means you are already in the In crowd.
- It means System Admins already feel comfortable with you.
- It means common folk have heard of you.
- It means people feel comfortable enough with you that they are willing to build an ecosystem around you and ecosystems make you more ubiquitous and pervasive.
How did MySQL get to that point and what tricks can PostgreSQL borrow from that experience?
- It ran natively on Windows before PostgreSQL did and Windows is a huge user-base especially for beta-testing. PostgreSQL has caught up there and is beginning to see the fruits of that labor.
- Everywhere you look for Mac etc. there are already pre-compiled binaries. Again PostgreSQL is catching up there with the Yum repository, pre-compiled windows binaries and valiant efforts of people making binaries for Mac, Debian, SUSE available. More work needs to be done there to insure binaries/rpms for latest releases are available for most of the OSes PostgreSQL supports and popular add-ons.
- MySQL is an easier install and easier to upgrade. As Joshua Drake pointed out in the above article, you can do in-place upgrades with MySQL, but really can't with PostgreSQL. Again PostgreSQL needs more work there. This is a huge plus for many ISPs and we know when many projects start out, they can't afford dedicated boxes so they rely on their ISPs to have these things already installed.
- You can run MySQL on a USB stick (or at least for windows) easily without having to reboot your pc. Portability is huge. Take a look at Server2GO its quite a slick run on USB that allows you to run Apache, MySQL, PHP and edit data on USB as well. It is all nicely packaged and allows a brain-dead user to point and click to use it. We need that for PostgreSQL and it seems there are efforts going on in that area which is good. LiveCD comes close but doesn't quite make the cut.
- A lot of people who used older versions of PostgreSQL have a bad taste in their mouth. People need to be reminded that PostgreSQL 6/7 of the past is vastly different from the PostgreSQL 8 series. You would think MySQL would have similar issues, but they seem to have less of that. That could be because official install repositories/ISPs have more updated versions of MySQL than PostgreSQL. Also MySQL has always been a relatively easy install and less threatening looking database for good or bad.
- Of course there is safety in crowds. People don't like to stand-alone because its okay to be wrong if everyone is wrong, but really lonely if you stand wrongly alone. MySQL's dominance makes it more dominant except in situations such as Open Source GIS where PostgreSQL/PostGIS is still a clear winner over MySQL and the dominant database for that growing niche market.
PostgreSQL has a lot of selling points that MySQL lacks, but this is a talk about why MySQL is so great, so we'll save that talk for another day.
PostgreSQL people look like a gang of geeks and Martin Mickos looks polished
PostgreSQL clan is heavily loaded with geeks and the first thing that comes to at least my mind is geek when trying to summarize the generic face of a PostgreSQL user. This is a good thing from a development standpoint and for attracting great developers, but is bad when a large constituency you are trying to sell to are not geeks and they perceive your database as a thing that only a geek can use effectively. While we would like to think otherwise and at least think that its in vogue to be a geek, most people are not geeks. We need to sell more to the otherside of the fence - because like it or not - they are often the ones that make the decisions.
Martin Mickos is riding on what Leo likes to call People who look alike play together rule of social behavior. He is forced to wear a suit like most money-decision making people and looks comfortable in that outfit. He looks like a CEO. He might be a geek inside but he covers it well, and he gives you the polished feel that he can endure the torture of a CEO recounting his golf game or bragging about his greatness. Why is this important? Isn't it all an act? Yes it is an act, but it sends the message - I know how to act right - when to open my mouth and when to keep it shut. This is incredibly comforting to a generic CEO, CFO or CIO type. Yes it does often come down to he got the contract not because his technology was better but because he had a better suit on, got drunk on his own cool-aid and could finish a sentence without saying "Uhmm".
Martin Mickos balances Michael "Monty" Widenius disposition well, whereas a lot of PostgreSQL folk look and sound like Monty with very few balancing Martin's to level the see-saw.
We don't have a very strong prominent non-geek face to offset this imbalance. We need a CEO friendly imposter. I would say the closest are some of the EnterpriseDb folk, but EnterpriseDb is a commercial offering so that can only get the clan so far.
It would help if core PostgreSQL had a prim and proper looking figure or a comedian like Steve Jobs, Larry Ellison, Marc Fleury (founder of JBOSS), or geekesses in disguise like Kim Polese (the woman behind SpikeSource, Marimba, and Java) who exudes subtle persuasion abilities or a quietly confident woman such as Diane Greene, CEO and CoFounder of VMWare. Some PostgreSQL folks come to mind that can be molded into some of those type figures, but they still have that geek suit on (the T-shirt and the long hair that appeals to geeky sysadmins who are not always allowed to make decisions). Steve Jobs is a geek, but one with style. His brat geek kid who never grew up and with an obsession with clean interfaces that look good is great marketing. Similarly Larry Ellison's farcical obsession with wardrobe, racing, womanizing and destroying competitors is equally entertaining. Marc Fleury seems to be a compromise between the Steve and Larry personalities and some others mixed in. He has an air of mystique, but he knows when to behave as well.
Kim Polese perfectly complemented the advanced geekism of James Gosling who wanted to call Java a stupid name like Oak.
Diane Greene is an equally neat woman. She is not pushy, doesn't quite look like everyone else, but enough to make one feel comfortable, and she has that look that just screams - I can lead an army of ships into war. She balances out the more behind the scenes personality of her husband, Mendel Rosenblum, co-founder and chief scientist of VMWare.
Bill Gates (please don't throw stones at me for listing Bill Gates as one of those we respect). We for the most part like Bill Gate's and admire him. Both he and Diane Greene are what I shall refer to as anchors. Another rule of social behavior is that people like to hang around anchors. Anchors are those people who have a horned or natural instinct for feeling out what makes their audience comfortable and becoming it. They don't quite dress like their audience, but are not vastly different enough to be scary. They stand out just enough to look different, but not too much. They seem as content being by themselves as they do with being with other people. You only need to look at video of Bill Gates last full day to see what an anchor he is.
A lot of PostgreSQL folk, from a cursory observation, are suffering from some form of geekism and while it is not something that is easy to cure or should be cured - we need to offset it more with at least people who can hide their disorder or highlight those who have it to such a ridiculous level that it serves as a natural parody.
Symptoms of this disorder include
- Preferring to discuss merits of technology approaches and insisting on silence over discussion of the daily weather and other idle banter.
- Telling very obscure jokes and laughing at your own jokes.
- Saying what is on your mind and making criticisms in a matter of fact way without thinking about how it affects other's feelings. Basically lacking social situational awareness.
e.g.
That was a really idiotic thing you did. You better have backed up your data or you are probably screwed.
instead of the less harsh
The best way I think to handle that would have been .... Did you make a backup?
Keep in mind quite a few people are obsessed with what other people think and feel and spend a lot of time tailoring their words, gestures, and dress codes to that. They get quickly insulted when they come across someone who seems fairly oblivious to that concern unless that someone can add a lot of comedy to insult. - Unable to feel or at least look comfortable in anything else but a T-Shirt.
- Uneasiness in non-geek crowds.
MySQL has a pluggable storage architecture
Now this one we wouldn't suggest bothering with, although we should probably dissect this thoroughly to understand better what value people see in this and what substitutions can be made and pointed out that PostgreSQL offers. Granted the camp is divided here. Personally the fact that some things are supported on one MySQL storage engine and not another MySQL storage engine makes MySQL somewhat unpleasant to work with. As Tom mentioned in his The Value of MySQL Storage Engines I suppose there is some charm that we just can't appreciate.
What's new and upcoming in PostgreSQL
PostgreSQL 8.4 goodies in store
The PostgreSQL 8.4 planned release is March 1, 2009 and is outlined in the PostgreSQL 8.4 Development plan. It has just passed its May 2008 commit fest milestone and is currently in its July 2008 Commit Fest. Lots of PostgreSQL Planet bloggers have started showcasing some of the new features in store. We will briefly list our favorite planned and already committed patches.
Things that seem likely
- Built-in simple replication - As Bruce Momjian mentioned in his blog PostgreSQL 8.4 is planning to have built-in log shipping master/slave replication. More details of that in Core Team on Replication thread. Mostly we are excited about this because it will be one less thing MySQLers and SQL Servers can hold over why they will never consider PostgreSQL because it has no built-in replication.
- RETURN QUERY EXECUTE This one already made the commit. While it seems small to some, we are very excited about the RETURN QUERY working with EXECUTE. That was one of the things that made RETURN QUERY of limited use in 8.3. Thanks to Pavel Stehule for that one.
- Function Stats - Hubert Lubaczewski has been highlighting a lot of new nifty features. Many psql enhancements. Function stats is our favorite of his list so far and is detailed in Waiting for 84 Function Stats
- With RECURSIVE This is another one that hasn't quite made it in yet but is in the July 2008 commit fest.
With Recursive. For people familiar with SQL Server 2005 - this is similar in
style to SQL Server Common Table Expressions (CTE). Not sure the equivalent in Oracle - I presume
Corresponding byCONNECT BY or something along that line. IBM DB2 also has something called common table expressions, but not quite sure how that works or if it is the same. - ANSI SQL 2003: table function support This one hasn't made it in yet but is under review. For those who use set returning functions extensively and are frustrated by having to create a type for each set returning function you create, you will appreciate this one. ANSI SQL 2003: table function support. Thanks go to Pavel again for this one.
Things not so likely
Now there are two other things we are looking forward to that sadly we fear may not make it into 8.4, but with the cycles of PostgreSQL we'll probably only need to wait an additional year as opposed to 3-5 years (with other DB product release cycles) to see these.
- Windowing functions - for things like moving averages, cumulative sums and other stats across large amounts of data this is important. Lots of people have talked about this and its one of those things that sticks out like a sore thumb for high-end users.
- MERGE for PostgreSQL 8.4 as noted here - arguably this is just a check-off item for us because once SQL Server 2008 comes out, PostgreSQL will be the only database we commonly work with that doesn't have this functionality.
PostgreSQL Q & A
Setting up PostgreSQL as a Linked Server in Microsoft SQL Server 64-bit Intermediate
We would like to thank Jeff Crumbley of IILogistics for providing many of these steps and informing us that Microsoft has finally released a 64-bit OLEDB for ODBC driver.
For those who have not experienced the torture of this situation - let me start with a little background. First if you are running SQL Server 2005 32-bit and wished to create a linked server to a PostgreSQL server, everything is hunky dory. If however you had a SQL Server 2005 64-bit server, you ran into 2 very annoying obstacles.
- Obstacle 1: There for a long-time was no 64-bit ODBC driver nor native driver for PostgreSQL. This obstacle was somewhat alleviated when Fuurin Kazanbai made experimental compiled 64-bit PostgreSQL ODBC drivers available which work for AMD and Intel based processors.
- Obstacle 2: All looked good in the world until you tried this in SQL Server 2005 64-bit and low and behold - you needed a 64-bit OLEDB provider for ODBC to use it in SQL Server 2005 64-bit. Yes we waited patiently for years for this piece to be available. We still love you Microsoft. Then as Jeff Crumbley pointed out - Microsoft released an OLEDB 64-bit provider for ODBC in early April 2008.
Below are the steps to get a PostgreSQL linked server working in SQL Server 2005 64-bit.
- Run WindowsServer2003.WindowsXP-KB948459-v2-x64-ENU.exe - (Available as of 4/4/2008 from: http://www.microsoft.com/downloads/details.aspx?FamilyID=000364db-5e8b-44a8-b9be-ca44d18b059b&displaylang=en) (If you are running Vista 64-bit or Windows 2008 64-bit these are included already (or possibly in SP1))
- Make the folder C:\Program Files\PostgreSQL\8.1\AMD64bin (seems to also work fine against 8.3/8.4 if you are running that) and place the dlls from psqlodbc_AMD64 available from http://www.geocities.jp/inocchichichi/psqlodbc/index.html There is a newer compiled 64-bit ODBC driver at http://code.google.com/p/visionmap/wiki/psqlODBC If you are using this newer driver the use PostgreSQL 64-bit ODBC Drivers for the driver name instead of what we have below. The newere driver doesn't seem to handle data type conversion quite as well as the older.
- Run the psqlodbcwAMD64.reg file
- Create a System DSN in the 64-bit Data Source (ODBC) - alternatively you can skip this and use and embedded file DSN in SQL Server 2005 that we will outline in the next step.
- Create a Linked Server in SQL Server - below is a sample script that creates a PostgreSQL Linked Server in Microsoft SQL Server
2005 64-bit.
After that you should see the linked server in SQL Server 2005 Management ->Server Objects ->Linked Server and from there you can fiddle further with the settings. You should also be able to expand the PostgreSQL linked server and see the tables and views.EXEC master.dbo.sp_addlinkedserver @server = N'NAMEOFLINKEDSERVERHERE', @srvproduct=N'PostgreSQL AMD64A', @provider=N'MSDASQL', @provstr=N'Driver=PostgreSQL AMD64A;uid=pguser;Server=pghost;database=pgdatabase;pwd=somepassword' /* For security reasons the linked server remote logins password is changed with ######## */ EXEC master.dbo.sp_addlinkedsrvlogin @rmtsrvname=N'NAMEOFLINKEDSERVERHERE', @useself=N'True',@locallogin=NULL,@rmtuser=NULL,@rmtpassword=NULL - To test out the linked server - you can run the sample query below in SQL Server:
SELECT * FROM OpenQuery(NAMEOFLINKEDSERVERHERE, 'SELECT * From information_schema.tables')
Keep in mind that the PostgreSQL 64-bit ODBC is marked as experimental, but we have had good success with it on an Intel processor based 64-bit Windows 2003 running SQL Server 2005 64-bit.
PostgreSQL Q & A
How to calculate Running Totals and Sums in SQL Intermediate
People have asked us how to calculate running totals a number of times; not a lot but enough that we feel we should document the general technique. This approach is fairly ANSI-SQL standard and involves using SELF JOINS. In a later article we shall describe how to calculate moving averages which follows a similar technique but with some extra twists.
Note that the below examples can also be done with a correlated sub-select in the SELECT clause and in some cases that sometimes works better. Perhaps we shall show that approach in a later issue. We tend to prefer the look of the SELF JOIN though and in practice it is generally more efficient since its easier for planners to optimize and doesn't always result in a nested loop strategy. Just feels a little cleaner and if you are totaling a lot of columns (e.g number of items, products) etc, much more efficient.
Question 1: Calculate running total for a customer by order but don't include in the total the current order amount?Solution 1:
This is one of the cases where the use of a SELF JOIN comes in handy. For this particular example we shall assume we have a table of orders and for each order, we would like to know for that given customer the total price of goods they have purchased prior to date of order. For sake of argument we shall assume the order_datetime has full timestamp of order so it is a fairly rare or non-existent situation that a customer will have 2 orders with the same timestamp.
SELECT n.customer_id, n.order_id, n.order_total,
SUM(o.order_total) As running_total
FROM orders n LEFT JOIN orders o
ON (o.customer_id = n.customer_id
AND n.order_datetime > o.order_datetime)
GROUP BY n.customer_id, n.order_datetime, n.order_id
ORDER BY n.customer_id, n.order_datetime, n.order_id;
Question 2: How to calculate running total for each day?
In this case we want to know the total profit of the company for each day and running total for each day including current day. In this case we can use the more efficient INNER JOIN since we know that the prior and including current will have the current order date as well. Its debateable if we need the ORDER BY in the subselect. That is mostly there to try to force the planner to materialize the subselect which would tend to be faster. The below query should work fine in MySQL 5 and above as well.
NOTE: if you tried such a thing in Microsoft SQL Server 2005 and below the below would not work for 2 reasons.
- SQL Server 2005 and lower does not like order bys in subselects so you will need to remove that OR use the (SELECT TOP 100 PERCENT * FROM orders ORDER BY order_datetime) hack. Anyrate forcing an order would probably not change the plan in SQL Server 2005. Haven't tried on beta of SQL Server 2008
- SQL Server 2005 and below have no Date data type. Date and Datetime with Timestamp were introduced in SQL Server 2008 so the CAST part will probably work in SQL Server 2008. In prior versions there is some messy code you have to write involving subtraction of time. This is a PostgreSQL blog so we will not go into that. But here is a good link that covers that messiness - http://weblogs.sqlteam.com/jeffs/archive/2007/01/02/56079.aspx.
To give SQL Server 2005 and above due credit - this would be done more efficiently using the windowing functions introduced in SQL Server 2005 and above and so would the above example.
Solution 2:
SELECT n.order_date, n.order_total, SUM(o.order_total) As running_total
FROM (SELECT CAST(order_datetime As date) As order_date,
SUM(order_total) As order_total
FROM orders
GROUP BY CAST(order_datetime As date)
ORDER BY CAST(order_datetime As date)) n INNER JOIN
(SELECT CAST(order_datetime As date) As order_date,
SUM(order_total) As order_total
FROM orders
GROUP BY CAST(order_datetime As date)
ORDER BY CAST(order_datetime As date)) o
ON (n.order_date >= o.order_date)
GROUP BY n.order_date
ORDER BY n.order_date;
Basics
Cross Compare of SQL Server, MySQL, and PostgreSQL
Comparison of Microsoft SQL Server 2005, MySQL 5, and PostgreSQL 8.3
The below is by no means an exhaustive comparison of these 3 databases and functionality may not be necessarily ordered in order of importance. These are just our experiences with using these 3 databases. These are the databases we use most often. If we left your favorite database out - please don't take offense. Firebird for one has some neat features such as its small footprint and extensive SQL support, but we have not explored that Db.
People ask us time and time again what's the difference why should you care which database you use. We will try to be very fair in our comparison. We will show equally how PostgreSQL sucks compared to the others. These are the items we most care about or think others most care about. There are numerous other differences if you get deep into the trenches of each.
For those looking to compare MySQL and PostgreSQL you may want to also check out http://www.wikivs.com/wiki/MySQL_vs_PostgreSQL
If you really want to get into the guts of a relational database and the various parts that make it up and how the various databases differentiate in their implementations, we suggest reading Architecture of a Database System by Joseph M. Hellerstein, Michael Stonebraker, and James Hamilton. Architecture of a Database System focuses mostly on Oracle, DB2, and SQL Server but does provide some insight into MySQL and PostgreSQL.
People have pointed out things we omitted and things we got wrong, so we have corrected some of these and will be slowly adding updates.
A lot of people have been making comments on the related Reddit Cross Compare of SQL Server, MySQL, and PostgreSQL thread in addition to this blog. I guess it shows people are really passionate about their databases. Lots of good discussion.
| Feature | Microsoft SQL Server 2005 | MySQL 5 | PostgreSQL 8.3 |
|---|---|---|---|
| OS - Why is this important? Why would you even dream of not running on Windows? If you decide one day that Microsoft is not your best friend in the whole wide world, you can ditch them or at least on your DB Server (could that ever happen?). On a side note, Microsoft can't compete with Oracle on Linux/Unix anyway. If Microsoft has a non-Microsoft DB running on a customer's box, I wonder which database they would prefer - Oracle, IBM DB2, Sun MySQL or PostgreSQL? | Windows XP, Windows 2000+ | Windows (even down to 98?), Linux, Unix, Mac | Windows 2000+, Linux, Unix, Mac |
| Licensing | Commercial - Closed Source, Various levels of features based on version, Free Crippleware | GPL Open Source, Commercial. Here is an interesting blog entry on the subject MySQL free software but not Open Source. The comments are actually much more informative than the article itself. | BSD Open Source |
| Install/Maintenance Process | Hardest most time-consuming and biggest hog of resources of the 3 even when its not doing anything | Easiest | Medium |
| Drivers already installed on Windows | Yes - when you have a windows shop this is huge especially when you are not allowed to install stuff on client desktops and you need to integrate seamlessly with desktop apps. This is why using SQL Server Linked Server to get at yummy features of PostgreSQL comes in handy. | No | No |
| ODBC, JDBC, ADO.NET drivers available | Yes | Yes | Yes |
| Read-Only Views | Yes | Yes | Yes |
| Open Source products available for it | Few except CodePlex/.NET | Many | Few but ramping up and in PHP more than SQL Server |
| Commercial | Many? | Moderate | Few but ramping up |
| Updateable Views | Yes - even for 2 table views will automatically make them updateable if they have keys and update does not involve more than one table. You can write instead of triggers against more complex views to make them updateable | Yes - Single one table views are automatically updateable, some 2 table views are updateable if they don't have left joins and don't involve update of more than one table. If you have more complex views you want to make updateable - good riddance - no support for triggers or rules on views. | Yes, but not automatic. You have to write rules against views to make them updateable but can make very complicated views updateable as a result |
| Materialized/Indexable Views | Yes but varies slightly depending on if you are running SQL Express, Workgroup, Standard, Enterprise and numerous restrictions on your views that makes it of limited use | No? | No, but there are I think 2 contrib modules e.g. matviews that are simple and basically rebuild the materialized view |
| Can add columns and change names, data types of views without dropping | Yes | Yes | No - and extremely annoying if you have views that depend on other views. |
| Can drop tables, (drop, change size, data type of columns), and views used in views - this is a arguably a misfeature but sometimes it comes in handy when you are an EXPERT user :) | Yes - yikes! (but if you schema bind your tables and views, you can not drop dependent objects) | Yes - yikes! | No |
| Graphical View Designer (e.g. you can see tables and select fields drag lines to do joins) included no additional charge | Yes via SQL Management Studio and Express? | No | No |
| Computed Columns | Yes - but we still like using Views more except when we really need the computed column indexed and often we just do triggers. Computed columns are of very limited use since they can't hold roll-ups. | No - but looks like its slated for future release | No - but PostgreSQL has functional indexes so just use a view. |
| Functional Indexes - indexes based on a function | No - but you can create a computed column and create an index on it | No | Yes |
| Partial Indexes - e.g. you want to create a unique index but only consider non-null values | No - but as pointed out you can achieve similar results with an indexed view | No | Yes! |
| ACID compliance - do I dear say this is sometimes over-rated - not all data is created equal and sometimes bulk-insert speed is more important than ACID | Yes | Some storage engines e.g. InnoDB and not MyISAM | Yes |
| Foreign Key - Cascade Update/Delete | Yes | InnoDB and not MyISAM | Yes |
| Multi Row value insert | No - but SQL Server 2008 will have it | Yes | Yes |
| UPSERT logic - where you can simultaneously insert if missing and update if present | No - but SQL Server 2008 will have it via MERGE UPDATE | Yes - via INSERT IGNORE and REPLACE | No |
| Replication - haven't used much except for SQL Server so this is mostly hear-say | Yes - all sorts - log shipping, mirroring, snapshot, transactional and merge etc. and can even have non-SQL Server windows-based subscribers. Its still a bear to get working the way you want it and makes making structural changes difficult. Built-In | Yes - including master-master (built-in) See comments below and from numerours reports a big selling point of MySQL. | Yes but from reports seems to be the least polished of the bunch, although numerours third-party options to choose from that are both free and non-free. PostgreSQL 8.4 or higher is slated to have built-in replication - see core team notes - http://archives.postgresql.org/pgsql-hackers/2008-05/msg00913.php |
| Can program stored procs/functions in multiple languages | Yes - any language that complies with CLR -e.g VB.Net, C#, IronPython - but you need to compile into a dll first - so kind of cheating since you can't see python code right in your db. Upside you don't need IronPython etc. hosted on server, but you can't use the rich environment of Python either and need to have all dependent libraries explictly loaded into SQL Server GAC, a real PITA if you have lots of these dependencies. | No (except C and Pl/SQL) but they are working on it | Yes - PostgreSQL just does it the cool way - we like having our code right there where we can see what it is doing. Downside server must host the language environment. |
| Can define custom aggregate functions | Yes - any .NET language, but not TRANSACT SQL. Why is Transact-SQL thrown out to dust like this? | Yes but only in C as UDF | Yes - any PL language and built-in C, SQL, PLPgSQL. |
| Triggers | Yes | Yes | Yes |
| Table Partitioning | Yes - only Enterprise version - functional, range | Yes? (only applied to NDB cluster), 5.1 will be vastly improved | via Table Inheritance, Constraint Exclusion, RULES and Triggers - basically RANGE. Issues with using foreign-key constraints with inherited tables (plans to improve for 8.4?) |
| Can write Set/Table returning functions that can be used in FROM clause | Yes | No | Yes |
| Support creation of functions - e.g. CREATE FUNCTION | Yes | Yes | Yes |
| Support creation of stored procedures - e.g. CREATE PROCEDURE | Yes | Yes | Sort-Of - CREATE FUNCTION serves the same need |
| Dynamic and action SQL in functions | No - but you can in Stored procedures but you can't call stored procs from SELECT statements so much more limiting than PostgreSQL | No, but can in Stored procedures which aren't callable from SELECT statements so more limiting than PostgreSQL | Yes! - you can do really cool things with action functions in SELECT statements |
| Graphical Explain Tool - no additional charge | Yes - SQL Management Studio/Express | No | Yes - PgAdmin III |
| Job Scheduling Agent controllable from DB Manager client, for running batch sql and shell jobs - no additional charge (not CronTab) | Yes - SQL Agent (not for Express) | No - but upcoming 5.1 will | Yes - PgAgent |
| Access tables from other databases on same server | Yes - server.db.schema.table, can even access disparate data sources via linked server or open query | Yes - db.table, but not easily across servers | Sort of - via Dblink, but much less elegant than MSSQL and MySQL way and much less efficient. Can also access disparate data sources via DBI Link |
| Case-Insensitivity - e.g. LIKE 'abc%' and LIKE 'ABC%' mean the same thing | By default its not case sensitive, but can change this down to the column level. | It is not case-sensitive by default | By default is case-sensitive and a pain to make it not so. Sure you can do ILIKE, but its not indexable and just not the same since an ODBC driver doesn't expose it and is not ANSI compliant. This makes it annoying in environments like MS Access, PHP Gallery where MySQL/MSSQL Server default case insensitivity is more user expected. |
| Date Time support | SQL Server 2005 and below are just really lame. Only have Datetime (no support of timezone or just plain DATE). SQL Server 2008 will have these. | Less lame, has Date and DateTime but none with Timezone | Best - Date, TimeStamp and TimeStamp with Timezone (not to be confused with MySQL's timestamp which autoupdates or SQL Server's deprecated timestamp which is a binary) |
| Authentication | Standard Db security and NT /Active Directory Authentication | Standard Db with table-driven IP like security | Extensive - standard, LDAP, SSPI (can tie in with Active Directory if running on NT server, but still not quite as nice as SQL Server seamless integration), PAM, trust by IP, etc. |
| DISTINCT ON | No | No | Yes |
| WITH ROLLUP | Yes | Yes | No |
| WITH CUBE | Yes | No | No |
| Windowing Functions OVER..PARTITION BY | Yes | No | No |
| COUNT(DISTINCT), AGGREGATE(DISTINCT) | Yes | Yes | Yes |
| OGC Spatial Support - for the My dad is better than your dad fight in the GIS world between SQL Server and PostgreSQL/PostGIS check out A look at PostgreSQL and ArcSDE, Also check out our companion critque of the 3 spatial offerings | No - well Open source MSSQL Spatial add-on has basic support but not as good as PostGIS. Numerous commercial vendors provide spatial extensions for SQL Server 2005 - e.g. Manifold.net, MapDotNet, ESRI ArcSDE come to mind. SQL Server 2008 will have built-in, and geodetic but a lot of functions that PostGIS has will be missing. | Yes - MBR mostly and spatial indexes only work under MyISAM. Limited spatial functions. Some commercial (MapDotNet, Manifold.net), Open source GIS tools gaining steam but still more behind PostGIS. | Yes - PostGIS is great and lots of spatial functions and fairly efficient indexing and lots of open source and commercial support and upcoming ESRI ArcGIS 9.3 supports it too. |
| Schemas | Yes | No | Yes |
| CROSS APPLY | Yes | No | No but can for the most part simulate by putting set returning C/SQL functions in SELECT clause and wrapping more complex functions in an SQL function body. |
| LIMIT .. OFFSET | No - has TOP and ansi compliant ROW_NUMBER() OVER (ORDER BY somefield) As Row --- where ..Row >= ... AND Row <= ... which is much more cumbersome to use | Yes | Yes |
| Advanced Database Tuning Wizard | Yes - SQL Management Studio recommends indexes to put in etc. Very sweet. NOT available for Express or Workgroup. | No | No |
| Maintenance Plan Wizard | Yes via SQL Management Studio - Workgroup and above. Very sweet. Will walk you thru creating backup plan, reindexing plan, error checking and schedule these for you via SQL Agent | No | No |
| Pluggable Storage Engine | No | Yes | No |
| Correlated Subqueries | Yes | Yes | Yes |
| FullText Engine - all 3 have it, but we don't feel right comparing since we haven't used each enough to make an authoritative comparison. Its annoying there is no set standard for doing Full Text SQL queries | Yes | Yes | Yes |
| Sequences /Auto Number | Yes - via IDENTITY property of int field | Yes - via AUTO_INCREMENT of int field | Yes - via serial data type or defaulting to next Sequence of existing sequence object - this is better than MySQL and SQL Server simple auto_increment feature. The reason it is better is that you can use the same sequence object for multiple tables and you can have more than one per table. In the past PostgreSQL sequence was a pain but now you just create it with data type serial if you want it to behave like SQL Server and MySQL and it will automatically drop the sequence if you drop the table it is bound to. |
PL Programming
Choosing the right Database Procedural Language PL Beginner
One of the great selling points of PostgreSQL is its pluggable PL language architecture. MySQL is known for its pluggable storage and PostgreSQL is known for its pluggable PL language architecture. From Monty's notes on slide 12 looks like MySQL may be working on a pluggable PL language architecture of their own. The most common of these languages are the all-purpose languages SQL and C (these are built-in and not really PLs like the others, but we'll throw them in there), PLPgSQL which is also built-in but not always enabled, PL/Perl, PL/Python, and the domain specific languages PL/R, PL/SH and gaining popularity Skype released PL/Proxy. There are others in the family such as PL/Tcl, PL/PHP, PL/Ruby, PL/Scheme (a dialect of Lisp), PL/Java, PL/Lua and PL/LOLCode (for kicks and as a reference implementation. Think of LOLCode as PostgreSQL Pluggable PL equivalent of MySQL's BLACK HOLE storage engine.) .
The other interesting thing about the PostgreSQL PL language architecture is that it is a fairly thin wrapper around these languages. This means the kind of code you write in those languages is pretty much what you would write if you were doing general programming in those languages minus some spi calls. Since the handler is a just a thin wrapper around the environment, the language environment must be installed on the database server before you can use the PL language handler. This means you can have these functions utilized in your SQL statements and you can write in a language you feel comfortable with if you can get the darn PL compiled for your environment or someone has already kindly compiled it for your environment or that it is even compilable for your environment. The pluggable PL architecture means you can write a PL Handler for your favorite language or invent your own language that you can run in the database. In the end the barrier between code,data, and semantic constructs is more of a constraint imposed by compilers. If you have any doubts about the above statement, you need only look at some javascript injection attacks to bring the statement home. One of my fantasies is developing a language that morphs itself, that utilizes the database as its morphing engine and its OS and that breaks the illusion of data being data, code being code, and lacks rigid semantics. Of the languages we have worked with, SmallTalk comes closest to a language that satisfies these ideals and Lisp to a much lesser extent. Lisp lacked the semantic elegance of SmallTalk among other things.
Most people are used to having their procedural language push their data around. PL code living in PostgreSQL allows your data to push your procedural code around in a set-based way. This is a simple but pretty powerful feature since data is in general more fluid than code. For interpretated/just-in time compiled languages it can live in the database, for compiled it has to call compiled functions.
Now I shall stop here and say there are consequences to a thin wrapper that are both good and bad.
- Good/Bad - you are writing code you are used to. This is good because it makes people just getting used to relational database concepts feel at home. This is bad because it gives one the false confidence that the Romans will be happy when you impose your cultural bad habits on their perfect society. It is great to bring new ideas into the database, but try not to destroy the sanctity of the database by forgetting that you are in a database. Similar things have been said by DB programmers when SQL Server 2005 introduced .NET code in the database and you had all these reckless programmers doing things in .NET code that would have been more efficient in Transact-SQL. Just because you can do it doesn't mean you should. More on that later.
- Good - you can leverage all the goody libraries in your language of choice that others have written or you have written by calling the libraries from your database. With some caveats e.g. markings as safe and unsafe.
- Bad - PostgreSQL is doing a context switch to push the code into the environment your code is comfortable in. Generally the bigger and more complex the environment the more context switching that is happening.
- Bad - In order to manipulate data, except for the built in languages SQL, PlPgSQL, and C, PostgreSQL functions generally need to push the data into the language's environment and pull it out. This makes most languages somewhat suboptimal for set returning functions or functions that consume a lot of data.
As we mentioned in a prior article Trojan SQL Function Hack - A PL Lemma in Disguise not all languages are created equal as far as PostgreSQL is concerned and PostgreSQL has its favorites. Just as annoying as the MySQL storage engine idiosyncracies where you can have foreign keys in one storage engine and they are ignored in another, similar can be said with PL languages in PostgreSQL - they all handle sets differently and set returning functions are easier to write in some PL's than in others. Not to mention each programming environment has certain idiosyncracies of its own which make this useful yet still Leaky abstraction apparent.
Even if PostgreSQL did not have its favorites, one must keep in mind that languages are designed for a particular reason. They are designed to satisfy a particular language designers philosophies and goals. This means that Perl is optimized for the certain kinds of problems that Larry Wall liked to solve (e.g. string manipulation) and to solve them the way that Larry thought was fitting. Similarly R, S, S-Plus were designed for scientific, statistical processing, graphing. R takes some effort to get used to its terminology of data frames and factors and its way of pushing data into arrays and defining functions, but its well-worth it for what it does. Generally speaking the PL languages are not optimized for pushing data in a SET-oriented way and if you try to use them for something they were not really designed well for, you may feel comfortable but your database will suffer for your illusion of comfort. This false comfort leads people to write otherwise simple SET code in PlPython when it could have been done more efficiently and simply in PostgreSQL SQL function language or PLPgSQL language. Some people further like to encapsulate things in functions that shouldn't be encapsulated in functions in the first place because it gives them a false sense of comfort to shove stuff that they couldn't figure out how to write in a set-based way into a loop-di-loop blackbox. It may be amusing to write needlessly complicated code and kill cockroaches with hammers, but it is not a terribly efficient way of occupying your time. In fact the most impressive programmers are just clear thinkers. The real geniuses in programming are those who can restate an unsolvable problem into a solvable one or don't get caught up in the mob thinking that causes groups of people to simultaneously come up with the wonderful idea of solving the same wrong problem.
General rule of thumb when deciding which language to program a particular functionality
- Can you do the same thing in plain old SQL language? If you can you should. SQL functions are generally inlined which makes them more efficient from a planner perspective
- Most people don't feel comfortable writing in C - so you may want to throw this out of the equation although it is close in priviledge to SQL functions and for intense processor functions more efficient
- Does the function require some intensive calculation or functionality that doesn't exist in PostgreSQL or that is just faster to write and process in PLPerl, PL/R or that these languages have built-in already etc.? Here you probably want to do some benchmarks to be sure to make sure the lose in context switching is less than the gain in efficiency.
- Will you have to run this database in an environment that doesn't support your poison of choice?
- Do you feel comfortable in X language and does it look like something you can feel comfortable with.
Below are links to various articles that demonstrate some uses of PLs :
- David Fetter's A Babel of PLs PG 2007 presentation - complete list of presentations and link to audio file can be found at http://www.postgresqlconference.org/2007/talks/
- Joe Conway's 2003 Oscon presentation on PL/R - this is dated but still well worth a read.
- Prepared statements gotcha - (not quite intention of this article) - Hubert provides a PLPerl function called random_username() which is a very good use case of using PLPerl.
- Wiki PL Matrix provides status of existing PostgreSQL PLs.
Application Development
REST in PostgreSQL Part 3 A - Simple REST Client in Adobe Flex 3 Intermediate
In prior articles of this series, we covered the following:
- Showcasing REST in PostgreSQL - The PreQuel we went over what REST is and isn't
- REST in PostgreSQL Part 1 - The DB components we loaded the Pagila database and created a db plpgsql search function to support our rest server service
- REST in PostgreSQL Part 2 A - The REST Server service with ASP.NET we demonstrated a REST web service using Mono.NET, MS.NET both in C#, VB.Net/Monobasic
- REST in PostgreSQL Part 2 B - The REST Server service with PHP 5 we demonstrated a REST web service using PHP 5
What is Adobe Flex?
Adobe Flex is the development API for developing standard Flash and Adobe Air applications which Adobe calls Rich Internet Applications (RIA). Adobe Air run as desktop apps and regular Flex Flash apps run in a browser. At its core is ActionScript 3 which one can think of as a language that is a cross between Javascript and Java. It is more type sensitive than JavaScript but less so than Java. Flex is basically Adobe's effort at minimizing the a tool for building bouncing balls and other pointless but pretty graphic effects image of Flash and having it do real work that would cater more to application developers.
Its a fairly direct competitor to Microsoft's SilverLight, and is a more mature platform than Microsoft's SilverLight. Granted it is less ambitious. For example you can only program in ActionScript on the client (which is compiled into a binary) and interact via JavaScript where as Microsoft's SilverLight 2 incarnation promises ability to program in numerous languages on both Client and Server. Both strive to bring the responsiveness of a desktop app to the web. Flex also has an advantage in that most user's have the Flash Player installed which is supported on most OS. SilverLight will require an additional 3-5 MB download and is supported on Windows/Mac by Microsoft and will be deployable on Linux/other Unix/PDAs Platforms via Novell's MoonLight implementation.
Tools for developing Adobe Flex apps
You can develop Adobe Flex with notepad, VIM, emacs or any other favorite editor and compile with the freely available Adobe Flex 3 SDK. If you prefer having a more advanced IDE, there are 2 options that come to mind that we have tried.
- Flex Builder download from http://www.adobe.com/cfusion/entitlement/index.cfm?e=flex3email - this is Adobe's IDE for Flex development. Flex Builder is built using the Eclipse Framework and can be installed as a standalone or as part of the Eclipse IDE. Flex sports What you see is what you get (WYSIWIG) functionality, intellisense, on the fly error handling, compile on save. It costs about $800, but has a 60-day trial version. We presume this should work anywhere you have a Java runtime 1.6 or above.
- FlashDevelop - download from http://www.flashdevelop.org/community/viewforum.php?f=11
- This is a freely available Open Source Flex IDE. It lacks the WYSIWIG functionality of Flex Builder, but similar to Flex Builder, sports intellisense for both action script and Adobe application XML and simple compile with click of a button, error handling response. It is built using .NET Framework 2.0 and Sharp Develop. Haven't tried this in Linux so not sure if it works under Mono. It does work on MacOSX according to reports.
Setting up FlashDevelop IDE Environment
For this exercise, we will be using FlashDevelop. WYSIWIG IDEs always make us feel like we are giving up responsiveness to WYSIWIG and in many cases we find WYSIWIG to be a distraction from our core motive. For a simple app - WYSIWIG is not needed. For more decorative apps, you may be better going with Flex Builder.
To setup the development environment - do the following:
- Install Java 1.6 if you don't have it already - Flex3 SDK needs it
- Download FlashDevelop and install http://www.flashdevelop.org/community/viewforum.php?f=11. We are using the 3.0.0 Beta 7 version.
- Download Flex 3 SDK from http://www.adobe.com/cfusion/entitlement/index.cfm?e=flex3email. Keep in mind you do not need Flex Builder which is also downloadable from this page and over 300 MB.
- Extract flex3sdk into some folder.
- Install FlashDevelop (Note you will need .NET Framework 2 for this)
- Launch FlashDevelop
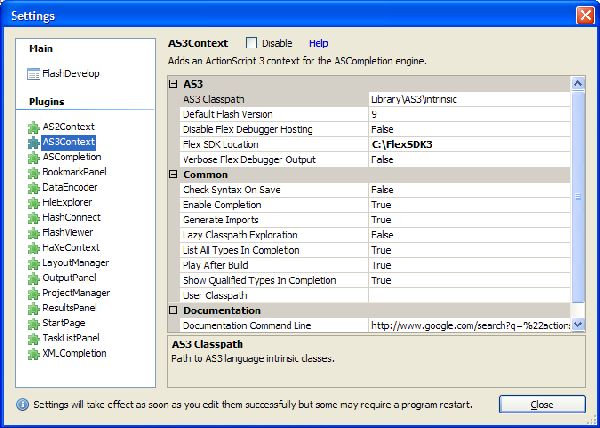
- Go to Tools -> Program Settings -> Select AS3Context and set FlexSDK Location to where you extracted the SDK as shown
Building Pagila Search Adobe Flex Client in FlashDevelop
To build a Pagila Search client that will use our REST Server service, we do the following:
- Click on New Project from FlashDevelop Recent Projects dashboard -
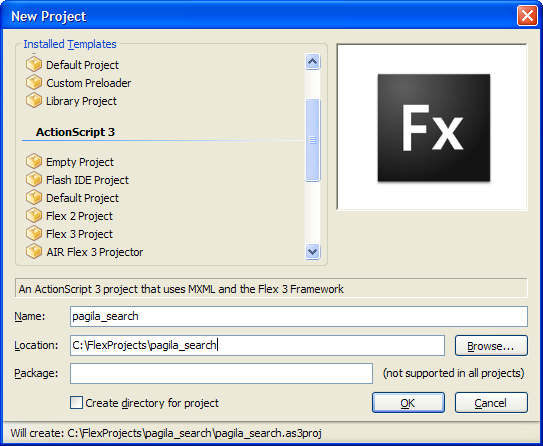
- Select Flex 3 Project and specify the path to store the project files as shown in the picture -
- On menu tab select -> Project -> Properties -> Test Movie - set to Play in Flash Viewer
The IDE creates a rudimentary Main.mxml file in the src folder and sets it to always compile. We shall for simplicity put all our code in this file.
Open up this file and replace the contents with the below.
<?xml version="1.0" encoding="utf-8"?> <mx:Application xmlns:mx="http://www.adobe.com/2006/mxml" layout="vertical"> <mx:Script> <![CDATA[ import mx.collections.ArrayCollection; import mx.rpc.events.ResultEvent; import mx.rpc.events.FaultEvent; import mx.controls.Alert; [Bindable] private var sresults:ArrayCollection; private var numresults:String; public function handleXml(event:ResultEvent):void { numresults = event.result.results.resultsummary.count; txtResultStatus.text = numresults + " items fit your search criteria"; if (numresults == "0") { sresults = null; } else { sresults = event.result.results.table.row; } } public function handleFault(event:FaultEvent):void { Alert.show(event.fault.faultString, "Error"); } ]]> </mx:Script> <mx:HTTPService id="xmlRpc" url="http://localhost:8080/pagila_php.php" result="handleXml(event)" fault="handleFault(event)"> <mx:request> <query>{search.text}</query> <maxrecs>20</maxrecs> </mx:request> </mx:HTTPService> <mx:VBox> <mx:HBox id="HBoxUser" width="100%"> <mx:Label text="Search Terms" textAlign="right" fontWeight="bold" color="white" /> <mx:TextInput id="search" width="300" height="22" /> <mx:Button x="130" y="95" label="Search" click="xmlRpc.send()" width="160" height="22" /> <mx:Label id="txtResultStatus" fontWeight="bold" color="white" /> </mx:HBox> </mx:VBox> <mx:DataGrid id="grdResult" dataProvider="{sresults}" editable="false" variableRowHeight="true"/> </mx:Application>- Click F8 to build the project (this is optional since F5 will automatically build and play).
- Click F5 to run the generated flash file.
The above is a fairly brain-dead implementation. What it does is the following:
- Calls our REST Service. Which is hard-coded - you may want to dynamically set that.
- It looks at our XML resultsummary portion
... - If results are returned it loads them in a variable called sresults which then gets bound to our Flex grid. If none, then it sets sresults to null.
- Flex Grid provides out of the box grid sorting, column dragging, dynamic width change, and if you don't explicitly specify the columns it infers it from the datasource.
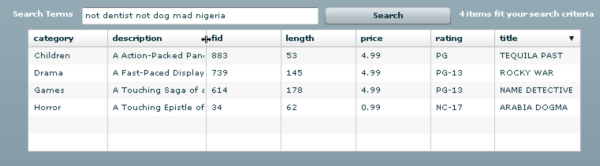
Below is a screen shot of our brain-dead implementation in action.
Deploy on webserver
To deploy the application on your webserver
- Copy the generated flash file from the bin folder of your FlashDevelop project to webserver
- Create an html file that looks something like this: Note for brevity we left out all the check for flash version etc.
<html lang="en"> <head> <title>My Pagila Search Client</title> <style> body { margin: 0px; overflow:hidden } </style> </head> <body scroll="no"> <object classid="clsid:D27CDB6E-AE6D-11cf-96B8-444553540000" id="pagilasearch" width="100%" height="100%" codebase="http://fpdownload.macromedia.com/get/flashplayer/current/swflash.cab"> <param name="movie" value="pagilasearch.swf" /> <param name="quality" value="high" /> <param name="bgcolor" value="#ffffff" /> <param name="allowScriptAccess" value="sameDomain" /> <embed src="pagilasearch.swf" quality="high" bgcolor="#ffffff" width="100%" height="100%" name="pagilasearch" align="middle" play="true" loop="false" quality="high" allowScriptAccess="sameDomain" type="application/x-shockwave-flash" pluginspage="http://www.adobe.com/go/getflashplayer"> </embed> </object> </body> </html>
Application Development
REST in PostgreSQL Part 3 B - The REST Client in Adobe Flex 3 with Paging Intermediate
In prior articles of this series, we covered the following:
- Showcasing REST in PostgreSQL - The PreQuel we went over what REST is and isn't
- REST in PostgreSQL Part 1 - The DB components we loaded the Pagila database and created a db plpgsql search function to support our rest server service
- REST in PostgreSQL Part 2 A - The REST Server service with ASP.NET we demonstrated a REST web service using Mono.NET, MS.NET both in C#, VB.Net/Monobasic
- REST in PostgreSQL Part 2 B - The REST Server service with PHP 5 we demonstrated a REST web service using PHP 5
- REST in PostgreSQL Part 3 A - Simple REST Client in Adobe Flex 3 we demonstrated a basic REST client in Adobe Flex
In this article we shall continue where we left off by adding paging functionality to our Adobe Flex REST grid client.
Put in Paging Drop Down
We have revised our code to deal with dynamic paging. The below code does the following:
- In the display portion, we have drawn a combo box to hold paging and initialize it to invisible.
- We have changed our webservice offset to be bound to a function of combo box index. Note the index denotes the page we want to pull.
- We need to do a bit more when the search button is clicked, so we have created a function called search_click() which will reset our offset and paging back to one. We do this because clicking Search triggers a new search
- In the combo box page drop down we have it to trigger the webservice call.
- During the webservice call, if the page combo is at 1 (meaning a new search), we redraw the combo as function of number of results.
Our revised application view and code is shown below.
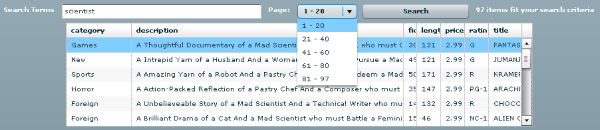
<?xml version="1.0" encoding="utf-8"?>
<mx:Application xmlns:mx="http://www.adobe.com/2006/mxml" layout="vertical">
<mx:Script>
<![CDATA[
import mx.collections.ArrayCollection;
import mx.rpc.events.ResultEvent;
import mx.rpc.events.FaultEvent;
import mx.controls.Alert;
[Bindable]
private var sresults:ArrayCollection;
private var numresults:String;
public function handleXml(event:ResultEvent):void
{
var i:int;
var npages:Array;
numresults = event.result.results.resultsummary.count;
txtResultStatus.text = numresults + " items fit your search criteria";
if (numresults == "0")
{
sresults = null;
cboPages.visible = false;
lblPage.visible = false;
npages = new Array(1);
npages[0] = '';
cboPages.dataProvider = npages;
}
else
{
sresults = event.result.results.table.row;
cboPages.visible = true;
if (cboPages.selectedIndex == 0){ //new search request
npages = new Array(int(int(numresults) / 20));
for (i = 0; i <= int(int(numresults) / 20); i++)
{
if ((i + 1) * 20 > int(numresults))
{
npages[i] = (i * 20 + 1) + ' - ' + numresults;
}
else {
npages[i] = (i * 20 + 1) + ' - ' + (i + 1) * 20;
}
}
cboPages.dataProvider = npages;
}
lblPage.visible = true;
}
}
public function handleFault(event:FaultEvent):void
{
Alert.show(event.fault.faultString, "Error");
}
public function search_click():void {
xmlRpc.request.offset = 0;
cboPages.selectedIndex = 0;
xmlRpc.send();
}]]>
</mx:Script>
<mx:HTTPService id="xmlRpc"
url="http://localhost:8080/pagila_php.php"
result="handleXml(event)"
fault="handleFault(event)">
<mx:request>
<query>{search.text}</query>
<maxrecs>20</maxrecs>
<offset>{int(cboPages.selectedIndex)*20}</offset>
</mx:request>
</mx:HTTPService>
<mx:VBox>
<mx:HBox id="HBoxUser" width="100%">
<mx:Label text="Search Terms" textAlign="right" fontWeight="bold" color="white" /> <mx:TextInput id="search" width="300" height="22" />
<mx:Label text="Page:" id="lblPage" textAlign="right" fontWeight="bold" color="white" visible="false" />
<mx:ComboBox id="cboPages" width="90" visible="false" change="xmlRpc.send()">
<mx:dataProvider>
<mx:Array><mx:String></mx:String></mx:Array>
</mx:dataProvider>
</mx:ComboBox>
<mx:Button x="130" y="95"
label="Search"
click="search_click()"
width="160" height="22" />
<mx:Label id="txtResultStatus" fontWeight="bold" color="white" />
</mx:HBox>
</mx:VBox><mx:DataGrid id="grdResult" dataProvider="{sresults}" editable="false" variableRowHeight="true"/>
</mx:Application>
Product Showcase
PHP Gallery 2 for Picture Storage and Simple Document Management Intermediate
What is PHP Gallery 2?
PHP Gallery 2 is a web-based management system for storing pictures and other documents such as movies and flash files. While it is not designed for storing documents such as Microsoft Word or PDF, it serves as a simple storage container for those as well and will even automatically create thumbnails for PDFs if you have ImageMagick installed. It is similar to Gallery 1 except unlike Gallery 1, the meta data of documents is stored in a database as opposed to the file system. Documents are still stored in the file system. Gallery is Open Source software licensed under GPL. Details here.
We've been using Gallery 2 for various projects over the past year or so because it has been fairly easy to integrate into our PHP applications. Below is the list of features we like most about it:
- Supports one of our favorite databases and those other 2 - PostgreSQL, MySQL, Oracle. Minor gripe - you can tell from the docs that there is a MySQL bias.
- Cross-Platform - will work anywhere PHP works.
- It uses PHP ADODB as the database abstraction layer.
- It uses Smarty Templating engine.
- Lots of Plugins to choose from - we'll go over our favorites later
- When you upload a high-res image it automatically creates 2 other sizes (thumbnail and regular web view)
People may ask when you've got Flickr and Picasa and all that other stuff, why would you ever go with Gallery 2. We haven't tried Flickr or those others, so we can't really speak of their merits or downfalls, but the reasons we prefer Gallery 2 over those other options is the same reason we prefer Serendipity Blogging engine over something like Google Blogger. We have more control, more seamless integration with our other database applications, and if you loose internet connection and are running an intranet, you are not out of luck.
Gallery 2 Gotchas when using PostgreSQL: Case Sensitivity when doing Search
Gallery 2 for our purposes has performed very nicely with PostgreSQL except for case-sensitivity when doing searches. People must think we are broken records by now. Here is a fine occasion where the case-sensitivity of PostgreSQL and as I recall Oracle - bites you. We have come up with 2 ways of overcoming this obstacle.
- Make PostgreSQL non-case sensitive - this we outlined in Using MS Access with PostgreSQL
- Make Gallery 2 compensate for Case Sensitivity - Hack the /modules/core/classes/GalleryCoreSearch.class -> search as described in this thread we posted to http://gallery.menalto.com/node/18076
Cool Plugins
A lot of the plugins require the following Graphics Toolkits
- Image Magick which has binaries available for Unix, Windows and Mac OSX. Image Magick is a very cool free open source graphics package that can be used within PHP, .NET, Perl etc. It resizes images, flips them, removes EXIFs, convert in-between various formats, even deals with CMYK images. Very cool. If you haven't used it and do a lot of graphical manipulation in your applications, I highly suggest you look into the 100s of features it offers.
- FFMPEG is used by Gallery for doing things like putting water marks on MPEG files and other MPEG manipulation
- Zip/Unzip is used by the shopping cart feature to allow a user to download a whole album or selected documents as a zip and the unzip is used by Gallery upload to allow a user to upload a batch of documents as a single zip that are then extracted. Each folder in the zip becomes a sub album. Linux/Unix machines already have this pre-installed. For windows users you'll need cygwin1.dll and the zip and unzip.exe that come with cygwin
Below are some of our highly recommended Plug-ins in addition to the Graphics Toolkits and pre-installed:
- Cart and Zip Download: Makes it easy for users to pick pictures they want and download High-Res versions
- Keyword Album: Allows you to have dynamic albums created based on Keywords you type in
- Flash Video, MP3 Audio: Allows these to be played right on the page and for Flash set the desired size
- Archive Upload: Allows uploading zip files and having them explode into albums and album items
- Numerous other upload plugins: XP Upload (for uploading from Windows XP Explorer), Picasa, etc.
- Javascript Slideshow
Special Feature
PostgreSQL 8.3 TSearch Cheat Sheet Overview Intermediate
Below is a Thumbnail view of a PostgreSQL 8.3 TSearch Cheat Sheet that covers PostgreSQL 8.3 Full Text search engine constructs.


This one we broke into two pages so its a bit more readable than our PostgreSQL 8.3 cheat sheet.
PDF landscape version 8.5 x 11" of this cheatsheet is available at PostgreSQL 8.3 TSearch Full-Text Search in PDF 8/12 by 11 and also available in PDF A4 format and HTML.