Table Of Contents
Manually setting table column statistics Intermediate
PostgreSQL 9.1 Trigrams teaching LIKE and ILIKE new tricks Intermediate
Using PgAdmin PLPgSQL Debugger Intermediate
From the Editors
New Additions and Promotions in PostGIS Development Team
This past week our PostGIS Project Steering Committee has gotten a wee bit bigger with the addition of Sandro Santilli and Chris Hodgson. So now we are 5 people strong. Though we have drastically different opinions on things, I think we all have the best interest of PostGIS users in mind such that the difference creates a healthy compromise in perspectives.
Our PostGIS development team has gotten a new addition as well. We have Bborie Park hailing from UC Davis Center for Vectorborne Diseases helping out on the raster front. You might have seen him on the PostgreSQL news groups asking questions. He is currently working on raster image export functions, so that you can do things like ST_AsPNG(rast,...) right from the database. In addition he is also working on raster statistics functions like histograms, mean, minmax, stddev, reclass functions.
Bborie, if you get some of this in for 2.0, I promise to help document these new functions and to write an ASP.NET and PHP application/tutorial that flaunts some of them.
Paul Ramsey keynoting at PgCon 2011
As Dan Langille already mentioned in his blog, PGCon 2011 has started. Our very own PostGIS action hero, Paul Ramsey, will be a keynote speaker. He's an introvert, so I have been told, which you probably can't tell by hearing him speak. I'm sure there is an extrovert in there trying to break loose. Anyrate he's one of the best speakers I've come across, so enjoy.
OpenStreetMap tutorial up
We have an OpenStreetMap tutorial up that demonstrates how to load OpenStreetMap (in this case Massachusetts data), into PostgreSQL/PostGIS called Loading OpenStreetMap data into PostGIS: An Almost Idiot's Guide Check it out. The nice thing is that cloudmade provides regional downloads broken out by country/state/ and so forth, so you don't have to download the whole OSM data file if you just need it for your particular region. We hope to follow up that tutorial with one on generating map tiles and using them with OpenLayers.
Part of the reason why we are more interested in OpenStreetMap is it knocks off a lot of tin cans with one stone, and there is nothing I enjoy doing more than knocking down many cans with a single sling shot. Just to name a couple of ways how this helps:
- We have a couple of projects planning or interested in exploring use of OpenStreetMap.
- It's a good way to test PostgreSQL 9.1 beta and PostGIS 2.0 with something that is not quite so trivial and can be made as heavy as you want it to be by loading more or less geographic regions.
- Great dataset for training purposes. I'm not sure why but people seem more engaged in learning when you relate it to topics they are interested in -- like themselves. I personally prefer imaginary things, but I realize I am abnormal.
- Eventually I would like to write a pure plpgsql geocoding solution based on OpenStreetMap structure and package it as an extra for PostGIS similar to what we have fo tiger geocoder. That will make it more usuable for non-US. Granted there are a couple of geocoders out there for PostGIS, but none to my knowledge aside from the Tiger Geocoder are pure plpgsql/PostGIS solutions so not quite as easy to install or call directly from PostgreSQL for batch geocoding right in the database.
From the Editors
PgCon 2011 Notes recap and more notes
Since others have shared their PostgreSQL Conference notes on Planet PostgreSQL: Josh Berkus, Blake Crosby, Selena Deckelman, Dmitri Fontaine, Bruce Momjian, Gabrielle Roth, Andreas Scherbaum, and Greg Smith, I thought I'd do my civic duty and add Paul Ramsey's notes to the mix. His are on his corporate OpenGeo blog which is carried by Planet Geospatial and Planet OSGeo but not by Planet PostgreSQL. One thing I admire about Paul is how easily he lets himself be changed by his environment. Sometimes you have to be a little careful what you say to him since he sometimes takes your comments a little too much to heart and changes a little bit more than you had intended. Anyrate here are his notes: PgCon Notes #1, PgCon Notes #2, PgCon Notes #3.
What's new and upcoming in PostgreSQL
State of PostGIS and PostGIS Windows binaries for 9.1 9.0 and 8.4
PostGIS 2.0.0 has inched a lot closer to completion. This past week, Paul enabled his gserialization work which changed the on disk-format of PostGIS and in return I think we'll have a much better platform to grow on. With this change we now have the 3D index and bounding box bindings in place. Say hello to the &&& operator which is like &&, but is 3D aware and comes with its own companion 3D spatial indexes. This will allow you to do true 3D bounding box searches with any of the new 2.5/3D geometries we have in place for PostGIS 2.0.0. We are still noodling out the semantics of boxes. Read Paul's call for action on the The Box Plan?, if you are interested. PostgreSQL 8.4 is the lowest supported version for PostGIS 2.0.0. It took a bit of squabbling between PSC members to make that decision, but I put my foot down and I think in the end was for the best to allow us to use new features, less platforms to test, and get rid of some unnecessary code.
PostGIS Windows 32-bit Experimental builds fresh off the presses
With all these changes, if you are running an earlier alpha release of PostGIS 2.0.0, you'll need to do a dump restore since the on disk format is now changed.
If you are on windows and want to give some of this all a test drive, you can download one of our PostGIS 2.0.0 Windows experimental builds. We still only have 32-bit builds. We have builds for PostgreSQL 8.4, PostgreSQL 9.0, and PostgreSQL 9.1 beta 2. The problems we faced in PostgreSQL 9.1 beta 1 were resolved in beta 2 so that most regress tests past except some minor ones involving stupid things like difference in line number marking of errors. Complement your PostgreSQL 9.1 beta 2 meal with a yummy large helping of PostGIS 2.0.0 goodness.
PostGIS Innovations
PostGIS team has been a very exciting and fast-paced team to work on; particularly these past couple of months. I feel like a kid in a candy factory trying out all these new great features as soon as they come out of the oven and thinking of the workflows they can improve or make possible.
- Raster
On the raster front, we have now ability to reproject rasters using transform function similar to what we have for geometry as well as various analytic like histograms, summary stats, and value counts. We also have the ability to export rasters to various image formats. Plus more to come before release. Bborie has been a great team player thus far with getting all these things done, and plans to do more before release such as ability to rasterize geometries. I've still got a ways to go to finish off the Raster section of the PostGIS documentation to hold up my end of the bargain.
From what I have seen and heard thus far from others using other tools and thinking about using PostGIS raster support to replace or supplement, we've already got many raster features unheard of in any other spatial database including Oracle Spatial. There are still some raster processes people commonly do in R that are either faster in R or not yet available in PostGIS, but even that is narrowing and R has the disadvantage of not being quite as seamless when trying to perform operations that involve both rasters and vectors. Same I think can be said about ESRI raster support, though I know much less about that animal. Nothing beats the slickness and brevity for flipping rasters and vector geometries like SQL. So hats off to all those who have worked on PostGIS Raster-- Pierre, Jorge, Bborie, Strk,Mat, David
- Topology
Sandro Santilli (strk) has been diligently working on Topology support to make our PostGIS topology more inline with SQL-MM standards. Andrea Peri has also been helping out a great deal with testing and providing some patches. I still hope to create a loader for TIGER data (which in itself is a topological model) very close in structure to PostGIS topology. Both systems are composed of edges, faces, and nodes as the basic building blocks. This will serve as both a good learning tool for topology, a good way to stress test the system with real world data, as well as providing useful data that people would want to work with anyway. Not sure if I will get to that before release, so might come as a separate add-on.
- Tiger Geocoder Finally got the loader fully functional on Linux/Unix I think and I have been surprised how many people have already started using it and posting bug reports and patches. We are still working on speed improvements that we are doing via our consulting work and will contribute back in the code base. It still intentionally works fine with PostGIS 1.5 since we are improving on it for clients currently using PostGIS 1.5. However some of the new changes we have made require 8.4 or higher.
- Much improved 3D Support - as mentioned before we have new 3D indexes, operators, functions and types (TINS, POLYHEDRAL SURFACES etc). Though I don't show it , this is the part that I am most excited about. I'm still fleshing out the ST_ASX3D - making enhancements and hope to release a tutorial showing how to create a simple web-based 3D query tool with x3dom and PostGIS.
- Shape file dumper /loaders get some love We now have transformation support in the shape file loader, multi-file import for the gui shapefile loader and some other goodies.
PostGIS 64-bit builds -- when are they coming?
First I must say aside from a few people who have whined, I don't get the sense that people care too much either way with running PostGIS under 64-bit PostgreSQL windows install. Our interest is mostly out of curiosity if it will work better than it does under 32-bit Windows. Despite most people's snide remarks about running PostgreSQL on windows, it works fairly well for many of our needs and the PostGIS speed is for the most part on par with the Linux speed. There are still many suites that only work on windows and where having both a Linux box and windows box to maintain is not worth the hassle for the marginal difference in speed.
Generating 64-bit builds for PostGIS is proving to be a bit more problematic than we had hoped. I guess you can say that about most things in life. We first started with an attempt at VS VC++ build and quickly gave up on that after running into too many road blocks. It also doesn't help that the process would be much more different than the PostGIS Unix like build structure in place which would mean we would be constantly playing catchup with keeping our VS in synch with the configure scripts etc. used by PostGIS.
Aside from that I don't particularly care much for the VS development environment since it feels a bit too heavy for my liking. I use it for ASP.NET development for its intellisense which I do just as well with Visual Web Developer Express in and never need to compile anything in it. So the whole compilation side and the idea of solutions etc seems pretty alien to me.
This brings us to Msys64 which is the mode we chose to take because it seemed least painful and also allows us to be able to work with the same tool chain that the rest of the PostGIS team works with. Hats off to Andrew Dunstan. Thanks to him PostgreSQL 9.1 just compiled out of the box with Msys64, so that worked fine and was an easy check-off. The proj library that PostGIS uses for transformation, also more or less compiled using some minor hacks provided on the bug list provided by Paul Ramsey and others. GEOS sadly a key component, we got far into the compile process before it started coughing up blood. Details of our steps are documented in Compiling using MingGW-w64 for both 32-bit and 64-bit. If anyone wants to give it a stab and cares to please do so. At this point we are tired of the whole thing and will retire our efforts for now since we've got more rewarding things to do with our time. GDAL we've had issues with, but didn't try again to see how insurmountable they are. The rest of the items in PostGIS tool chain aside from PostGIS itself, are pretty common variety that we shouldn't run into any obstacles with those.
PostgreSQL Q & A
Difference Between CURRENT_TIMESTAMP and clock_timestamp() and how to exploit them Intermediate
What is the difference between CURRENT_TIMESTAMP and clock_timestamp()
Answer:CURRENT_TIMESTAMP is an ANSI-SQL Standard variable you will find in many relational databases including PostgreSQL, SQL Server, Firebird, IBM DB2 and MySQL to name a few that records the start of the transaction. The important thing to keep in mind about it is there is only one entry per transaction so if you have a long running transaction, you won't be seeing it changing as you go along.
clock_timestamp() is a PostgreSQL function that always returns the current clock's timestamp. I don't think I'm alone in using it for doing simple benchmarking and other things where for example I need to record the timings of each part of a function within the function using pedestrian RAISE NOTICE debug print statements.
There is another cool way I like using it, and that is for a batch of records each with an expensive function call, benchmarking how long it takes to process each record. One of the things I'm working on is improving the speed of the tiger_geocoder packaged in PostGIS 2.0. The first root of attack seemed to me would be the normalize_address function which I was noticing was taking anywhere from 10% to 50% of my time in the geocode process. That's a ton of time if you are trying to batch geocode a ton of records. The thing is the function is very particular to how badly formed the address is so a whole batch could be held up by one bad apple and since the batch doesn't return until all are processed, it makes the whole thing seem to take a while.
So rather than looping thru each, I thought it would be cool if I could run the batch, but for each record have it tell me how long it took to process relative to the rest so I could get a sense of what a problem address looks like. So I wrote this query:
WITH ctbenchmark
AS
(SELECT *,
the_time - COALESCE(lag(the_time) OVER(ORDER BY the_time), CURRENT_TIMESTAMP) As process_time,
the_time - CURRENT_TIMESTAMP As diff_from_start
FROM (SELECT address_1, city, state, zip,
pprint_addy(normalize_address(coalesce(address_1,'') || ', ' || coalesce(city || ' ','') || state || ' ' || zip)) As pp_addr,
clock_timestamp() As the_time
FROM testgeocode LIMIT 1000) As foo )
SELECT *
FROM ctbenchmark
WHERE process_time > '00:00:00.016'::interval;
Which returned an output something like this:
address_1 | city | state | zip | pp_addr | the_time | process_time | diff_from_start
------------------+------------+-------+------- +-------------------------------------------+--------------+------------------
48 MAIN ST .. | S.. | MA | 021.. | 48 MAIN .. | 2011-05-10 03:24:43.078-04 | 00:00:00.032 | 00:00:00.032
15 ... | | MA | 018... | 15 GREN... | 2011-05-10 03:24:50.796-04 | 00:00:00.031 | 00:00:07.75 PostgreSQL Q & A
Manually setting table column statistics Intermediate
Question: How do you deal with bad stat counts?
You have a large table and the default planner stats collector underestimates distinct counts of a critical query column thus resulting in much less than optimal query plans. How can you manually set this?
PostgreSQL 9.0 introduced ability to set two settings on table columns: n_distinct and n_distinct_inherited which are described a bit in ALTER TABLE help.
The n_distinct is the estimated number of distinct values for that column with -1 or any negative number representing a percentage of estimated table count instead of a true count.
n_distinct_inherited is a setting useful for parent tables that denotes the estimated distinct count sum of all a parent's child tables.
By tweaking these settings when they are less than optimal, you can influence the query planner to produce better plans. Why this is necessary is mostly for large tables where the stat collector will not query the whole table to determine stats. The stats collector generally queries at most 10-30% of a table.
Determine If you need to set counts
It's always nice to have the stat collector do all these things for you especially if you have a table that is constantly updated and distinct counts can fluctuate a lot. For static tables you may just want to set them manually. So how do you know whether you should bother or not. Well you can check the current values the stats collector has with this query:
-- determine if your stats are fine - compare estimates with what you know they are --
SELECT tablename, schemaname, attname As colname, n_distinct,
array_to_string(most_common_vals, E'\n') AS common_vals,
array_to_string(most_common_freqs, E'\n') As dist_freq
FROM pg_stats
WHERE tablename = 'table_of_interest'
ORDER BY schemaname, tablename, attname;
You would then compare with your actuals
SELECT count(DISTINCT column_of_interest) FROM table_of_interest;
Will give you the current count.
Setting n_distinct and n_distinct_inherited
You may want to bump this up or down when you set the value. Next to set the column distinct count stats you would do something like below replacing 50 with the count you computed:-- set stats (non parent tables ) --
ALTER TABLE table_of_interest
ALTER COLUMN column_of_interest
SET (n_distinct=50);
-- set stats (parent tables in an inheritance hierarchy ) --
ALTER TABLE table_of_interest
ALTER COLUMN column_of_interest
SET (n_distinct_inherited=50);
Basics
Navigating PostgreSQL 9.1 beta 1 with PgAdmin III 1.14.0 Beta 1 Beginner
We've started to play with PostgreSQL 9.1beta and the PgAdmin III 1.14.0 Beta 1. We'll briefly go over the cool gems found in PgAdmin III beta 1. Most of the new features are for navigating the upcoming PostgreSQL 9.1. Well first obstacle we ran into was we can't get our favorite extension, PostGIS, to compile against PostgreSQL 9.1beta though it did with the alphas, so you won't be seeing any windows experimental builds until we resolve this issue. Details of ticket here? PostGIS 2.0 won't compile for PostgreSQL 9.1 beta1
Despite that minor set back, we decided to push on and navigate the new features by using PgAdmin III 1.14.0 as our Tour Guide. Below is a list of new features you can experience via PgAdmin III 1.14.0 Beta 1. I'm sure there are more we missed, but these are the ones that were most flashing.
Extensions
In PostgreSQL 9.1 there is a new way to install contribs and other extensions. This makes it very easy to uninstall without knowing what you are doing. I was happy to see that PgAdmin III 1.14.0 has integrated this in the interface. Now hopefully when a newbie asks us How do I install hstore, tablefunc, ltree or whatever and how do I know what contribs I have installed? it will be as clear as water. Here is what it looks like:
- New colorful Extensions icon - shows what extensions you have. Right click to add a new extension
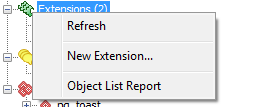
- Extensions dialog Right click to add a new extension
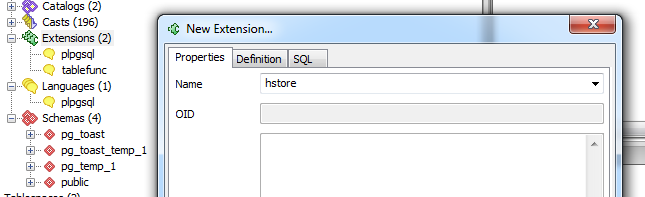
- Lets you choose which schema to install the extension
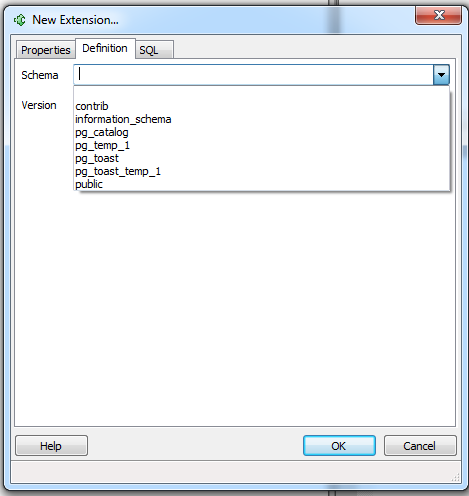 . For many of our smaller extensions, we usually create a
schema called contrib to install them in. What I really liked about this new feature is that if you accidentally installed the functions in the wrong schema -- say the default public, you
just have to right-click the extension, go to Definition tab and switch the schema. It automatically moves all the functions for you into the new schema.
. For many of our smaller extensions, we usually create a
schema called contrib to install them in. What I really liked about this new feature is that if you accidentally installed the functions in the wrong schema -- say the default public, you
just have to right-click the extension, go to Definition tab and switch the schema. It automatically moves all the functions for you into the new schema. - Most Extensions have just one version, but if there are multiple, the Definition tab will allow you to choose which version you want.
- What I have always loved about PgAdmin is the SQL tab which is on most any activity tab, which shows you the SQL you would need to run to script what you just did. It makes for
a really easy to use sql script generator and intro to new DDL commands.
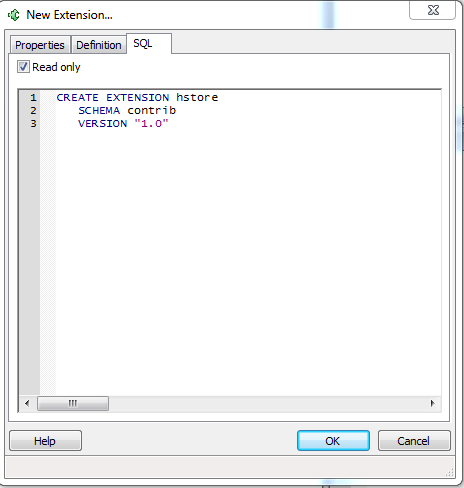
SQL/MED: Foreign Data: Accessing the option from PgAdmin
As many have already buzzed about SQL/MED (Management of External Data), you can now query more easily external data via the SQL-Standard SQL/MED protocol in PostgreSQL 9.1. The ability to do this with PgAdmin III is also present in 1.14, but not visible by default. In order to access this feature:
- Go to File -> Options -> Browser tab. Your screen should look something like:
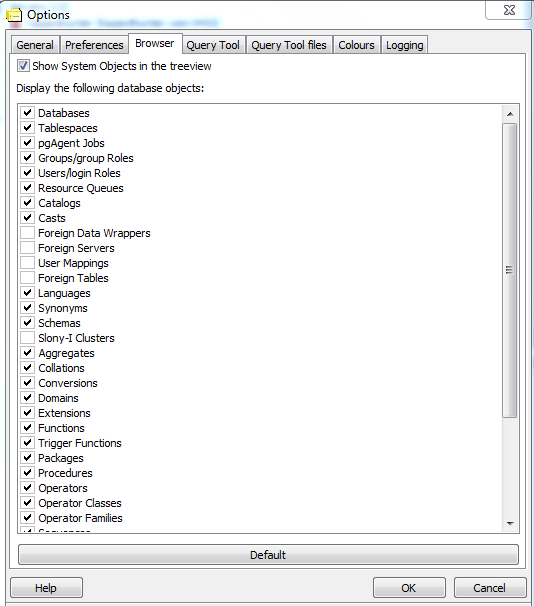
- The key pieces of SQL/MED are Foreign Data Wrappers, Foreign Servers, User Mappings, and Foreign Tables, so you'll want to check all these
- Disconnect from server and reconnect. Your should see next to your extensions icon a Foreign Data Wrapper icon
 .
In each schema -- you will also see a
.
In each schema -- you will also see a 
- There is a Foreign data handler (which you will need to define a wrap) already built-in for connecting to other PostgreSQL servers. In addition, for accessing flat files, there is another one you can install via the Extension icon called file_fdw. Add that one in to access flat files. This feature deserves its own article to demonstrate how to use it. You can expect to see that soon.
In an upcoming article. We;ll demonstrate how to connect to foreign data sources with the new SQL/MED feature.
New Table / View and column Usability features
The new table screen of PgAdmin has changed a bit to support the new features of PostgreSQL 9.1 as well as old features that you couldn't do without writing your own create table statement or changing the one generate. He re is a snapshot of definition tab.
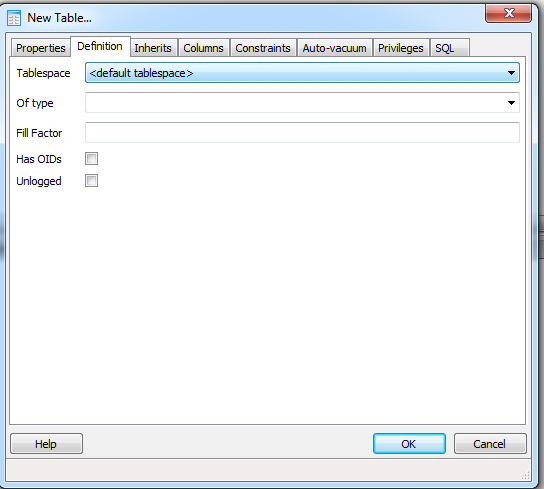
Unlogged tables is a new feature in PostgreSQL 9.1 that allows you to create non-transactional tables. Think of these as PostgreSQL equivalent of a better MyISAM.
It's good for data you need to be able to load fast but don't mind loosing in the event of a crash. As you can see, there is a Unlogged checkbox to create such a table
- PostgreSQL 9.1 now supports column level collations. To support this PgAdmin has collation drop down in the New Column screen, as well as an option to define new Collations in the tree.

- For table constraints, though we could create Exclusion Constraints in PostgreSQL 9.0, there was no PgAdmin interface to define them in the table constraint dialog.
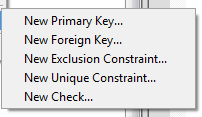
- View Triggers: Under views, we now have a trigger section to support the new feature in PostgreSQL 9.1 for using view triggers for updating.
Basics
PostgreSQL 9.1 Trigrams teaching LIKE and ILIKE new tricks Intermediate
There once existed programmers who were asked to explain this snippet of code: 1 + 2
- The C programmer explained "It's a common mathematical expression."
- The C++, Java, C# and other impure object-oriented programmers said "We concur. It's a common mathematical expression."
- The Smalltalk programmer explained "1 adds 2."
- The Lisp programmer stood up, a bit in disgust, and said, "No no! You are doing it all wrong!"
The Lisp Programmer then pulled out a Polish calculator, punched in+ 1 2,and with a very serious face, explained
"+ should be pushing those other two around."
I find this episode interesting because while the Lisp programmer I feel is more right, the Smalltalk programmer has managed to follow the rest of the crowd and still stick
to her core principle. This brings us to what does this have to do with trigrams
in PostgreSQL 9.1. Well just like 1 + 2 being a common mathematical expression, abc LIKE '%b%' is a common logical relational database expression that we have long taken for granted as not an indexable operation in most
databases (not any other database to I can think of) until PostgreSQL 9.1, which can utilize trigram indices (the Lisp programmer behind the curtain) to make it fast.
There are 2 main enhancements happening with trigrams in PostgreSQL 9.1 both of which depesz has already touched on in FASTER LIKE/ILIKE and KNNGIST. This means you can have an even faster trigram search than you ever have had before and you can do it in such a fashion that doesn't require any PostgreSQL trigram specific syntactical expressions. So while PostgreSQL 9.1 might be understanding LIKE much like all the other databases you work with, if you have a trigram index in place, it will just be doing it a little faster and sometimes a lot faster using the more clever PostgreSQL 9.1 planner. This is one example of how you can use applications designed for many databases and still be able to utilize advanced features in your database of choice. In this article we'll demonstrate.
For this example we'll use a table of 490,000 someodd records consisting of Massachusetts street segments and their names excerpted from TIGER 2010 data. You can download the trimmed data set from here if you want to play along.
The old story of using Btree Indexes
Normally if you plan to do LIKE searches, you would create a btree ops on the column or functional index on the upper/lower of the column. So here is the basic old in action:
CREATE INDEX idx_featnames_short_fullname_btree_ops
ON featnames_short USING btree (fullname varchar_pattern_ops);
vacuum analyze featnames_short;
-- takes 13ms returns 8 rows, uses btree ops index
SELECT DISTINCT fullname
FROM featnames_short
WHERE fullname LIKE 'Devonshire%';
EXPLAIN (ANALYZE true, FORMAT yaml)
SELECT DISTINCT fullname
FROM featnames_short
WHERE fullname LIKE 'Devonshire%';
- Plan:
Node Type: "Aggregate"
Strategy: "Hashed"
Startup Cost: 8.45
Total Cost: 8.47
Plan Rows: 2
Plan Width: 11
Actual Startup Time: 0.120
Actual Total Time: 0.121
Actual Rows: 8
Actual Loops: 1
Plans:
- Node Type: "Index Scan"
Parent Relationship: "Outer"
Scan Direction: "Forward"
Index Name: "idx_featnames_short_fullname_btree_ops"
Relation Name: "featnames_short"
Alias: "featnames_short"
Startup Cost: 0.00
Total Cost: 8.34
Plan Rows: 41
Plan Width: 11
Actual Startup Time: 0.024
Actual Total Time: 0.093
Actual Rows: 48
Actual Loops: 1
Index Cond: "(((fullname)::text ~>=~ 'Devonshire'::text) AND ((fullname)::text ~<~ 'Devonshirf'::text))"
Filter: "((fullname)::text ~~ 'Devonshire%'::text)"
Triggers:
Total Runtime: 0.161
-- takes 178ms returns 8 rows, uses no index
SELECT DISTINCT fullname
FROM featnames_short
WHERE fullname LIKE '%Devonshire%';
EXPLAIN (ANALYZE true, FORMAT yaml)
SELECT DISTINCT fullname
FROM featnames_short
WHERE fullname LIKE '%Devonshire%';
- Plan:
Node Type: "Aggregate"
Strategy: "Hashed"
Startup Cost: 9768.55
Total Cost: 9768.57
Plan Rows: 2
Plan Width: 11
Actual Startup Time: 125.773
Actual Total Time: 125.774
Actual Rows: 8
Actual Loops: 1
Plans:
- Node Type: "Seq Scan"
Parent Relationship: "Outer"
Relation Name: "featnames_short"
Alias: "featnames_short"
Startup Cost: 0.00
Total Cost: 9768.45
Plan Rows: 40
Plan Width: 11
Actual Startup Time: 24.995
Actual Total Time: 125.708
Actual Rows: 48
Actual Loops: 1
Filter: "((fullname)::text ~~ '%Devonshire%'::text)"
Triggers:
Total Runtime: 125.823
-- takes 869 ms returns 8 rows uses no index
SELECT DISTINCT fullname
FROM featnames_short
WHERE fullname ILIKE '%Devonshire%';
EXPLAIN (ANALYZE true, FORMAT yaml)
SELECT DISTINCT fullname
FROM featnames_short
WHERE fullname ILIKE '%Devonshire%';
- Plan:
Node Type: "Aggregate"
Strategy: "Hashed"
Startup Cost: 9768.55
Total Cost: 9768.57
Plan Rows: 2
Plan Width: 11
Actual Startup Time: 842.275
Actual Total Time: 842.276
Actual Rows: 8
Actual Loops: 1
Plans:
- Node Type: "Seq Scan"
Parent Relationship: "Outer"
Relation Name: "featnames_short"
Alias: "featnames_short"
Startup Cost: 0.00
Total Cost: 9768.45
Plan Rows: 40
Plan Width: 11
Actual Startup Time: 113.184
Actual Total Time: 842.190
Actual Rows: 48
Actual Loops: 1
Filter: "((fullname)::text ~~* '%Devonshire%'::text)"
Triggers:
Total Runtime: 842.320
The new way
Well in the new way the btree is sometimes faster for some LIKE scenarios, but can't be employed in all where as the trigram works for all. In the new way we supplement our btree with a trigram index or use a trigram index instead to do most ILIKE searches and LIKE '%me%' like searches. Here is the same exercise repeated with adding on a trigram index.
-- Install trigram module if you don't have installed already
CREATE EXTENSION pg_trgm;
-- Add trigram index (seems to take much longer to build if have btree 28 secs))
CREATE INDEX idx_featnames_short_fullname_trgm_gist
ON featnames_short USING gist (fullname gist_trgm_ops);
vacuum analyze featnames_short;
-- repeat the exercise
--takes 13 ms returns 8 rows (uses btree like other)
SELECT DISTINCT fullname
FROM featnames_short
WHERE fullname LIKE 'Devonshire%';
EXPLAIN (ANALYZE true, FORMAT yaml)
SELECT DISTINCT fullname
FROM featnames_short
WHERE fullname LIKE 'Devonshire%';
- Plan:
Node Type: "Aggregate"
Strategy: "Hashed"
Startup Cost: 8.44
Total Cost: 8.46
Plan Rows: 2
Plan Width: 11
Actual Startup Time: 0.121
Actual Total Time: 0.123
Actual Rows: 8
Actual Loops: 1
Plans:
- Node Type: "Index Scan"
Parent Relationship: "Outer"
Scan Direction: "Forward"
Index Name: "idx_featnames_short_fullname_btree_ops"
Relation Name: "featnames_short"
Alias: "featnames_short"
Startup Cost: 0.00
Total Cost: 8.34
Plan Rows: 40
Plan Width: 11
Actual Startup Time: 0.024
Actual Total Time: 0.092
Actual Rows: 48
Actual Loops: 1
Index Cond: "(((fullname)::text ~>=~ 'Devonshire'::text) AND ((fullname)::text ~<~ 'Devonshirf'::text))"
Filter: "((fullname)::text ~~ 'Devonshire%'::text)"
Triggers:
Total Runtime: 0.167
--takes 13 ms returns 8 rows - uses gist
SELECT DISTINCT fullname
FROM featnames_short
WHERE fullname ILIKE 'Devonshire%';
EXPLAIN (ANALYZE true, FORMAT yaml)
SELECT DISTINCT fullname
FROM featnames_short
WHERE fullname ILIKE 'Devonshire%';
- Plan:
Node Type: "Aggregate"
Strategy: "Hashed"
Startup Cost: 152.77
Total Cost: 152.79
Plan Rows: 2
Plan Width: 11
Actual Startup Time: 3.647
Actual Total Time: 3.649
Actual Rows: 8
Actual Loops: 1
Plans:
- Node Type: "Bitmap Heap Scan"
Parent Relationship: "Outer"
Relation Name: "featnames_short"
Alias: "featnames_short"
Startup Cost: 4.76
Total Cost: 152.67
Plan Rows: 40
Plan Width: 11
Actual Startup Time: 3.403
Actual Total Time: 3.613
Actual Rows: 48
Actual Loops: 1
Recheck Cond: "((fullname)::text ~~* 'Devonshire%'::text)"
Plans:
- Node Type: "Bitmap Index Scan"
Parent Relationship: "Outer"
Index Name: "idx_featnames_short_fullname_trgm_gist"
Startup Cost: 0.00
Total Cost: 4.75
Plan Rows: 40
Plan Width: 0
Actual Startup Time: 3.378
Actual Total Time: 3.378
Actual Rows: 48
Actual Loops: 1
Index Cond: "((fullname)::text ~~* 'Devonshire%'::text)"
Triggers:
Total Runtime: 3.720
-- takes 14-18 ms returns 8 rows uses gist bitmap index scan with heap scan
SELECT DISTINCT fullname
FROM featnames_short
WHERE fullname ILIKE '%Devonshire%';
EXPLAIN (ANALYZE true, FORMAT yaml)
SELECT DISTINCT fullname
FROM featnames_short
WHERE fullname ILIKE '%Devonshire%';
- Plan:
Node Type: "Aggregate"
Strategy: "Hashed"
Startup Cost: 152.77
Total Cost: 152.79
Plan Rows: 2
Plan Width: 11
Actual Startup Time: 5.586
Actual Total Time: 5.588
Actual Rows: 8
Actual Loops: 1
Plans:
- Node Type: "Bitmap Heap Scan"
Parent Relationship: "Outer"
Relation Name: "featnames_short"
Alias: "featnames_short"
Startup Cost: 4.76
Total Cost: 152.67
Plan Rows: 40
Plan Width: 11
Actual Startup Time: 5.351
Actual Total Time: 5.553
Actual Rows: 48
Actual Loops: 1
Recheck Cond: "((fullname)::text ~~* '%Devonshire%'::text)"
Plans:
- Node Type: "Bitmap Index Scan"
Parent Relationship: "Outer"
Index Name: "idx_featnames_short_fullname_trgm_gist"
Startup Cost: 0.00
Total Cost: 4.75
Plan Rows: 40
Plan Width: 0
Actual Startup Time: 5.325
Actual Total Time: 5.325
Actual Rows: 48
Actual Loops: 1
Index Cond: "((fullname)::text ~~* '%Devonshire%'::text)"
Triggers:
Total Runtime: 5.655
Some old rules still apply
If your queries are writtern something like below then the below query will not use an index:
-- This will not use an index --
SELECT fullname
FROM featnames_short
WHERE upper(fullname) LIKE '%DEVONSHIRE%';
There is no index above that will work for this, however if you put in an index on:
-- But if you do this the above uses an index again (14 ms - 8 rows)--
CREATE INDEX idx_featnames_short_ufullname_trgm_gist
ON featnames_short USING gist (upper(fullname) gist_trgm_ops);
What about citext and case insensitive LIKE found in MySQL and SQL Server
Sadly, we couldn't figure out how to get citext to use an index regardless of what we did. Though the hack we described a while ago of turning your PostgreSQL varchar() columns into case insensitive columns and putting a trigram gist index on upper(fullname) seems to work just dandy.
--finishes in 13-17ms and returns 9 rows
--(using CASE INSENSITIVE OPERATORS HACK for varchar columns) --
SELECT DISTINCT fullname FROM featnames_short WHERE fullname LIKE '%devonshire%';
- Plan:
Node Type: "Aggregate"
Strategy: "Hashed"
Startup Cost: 4113.74
Total Cost: 4114.62
Plan Rows: 88
Plan Width: 12
Actual Startup Time: 2.848
Actual Total Time: 2.850
Actual Rows: 9
Actual Loops: 1
Plans:
- Node Type: "Bitmap Heap Scan"
Parent Relationship: "Outer"
Relation Name: "featnames_short"
Alias: "featnames_short"
Startup Cost: 138.38
Total Cost: 4106.67
Plan Rows: 2825
Plan Width: 12
Actual Startup Time: 2.725
Actual Total Time: 2.826
Actual Rows: 51
Actual Loops: 1
Recheck Cond: "(upper((fullname)::text) ~~ 'DEVONSHIRE%'::text)"
Plans:
- Node Type: "Bitmap Index Scan"
Parent Relationship: "Outer"
Index Name: "idx_featnames_short_ufullname_trgm_gist"
Startup Cost: 0.00
Total Cost: 137.67
Plan Rows: 2825
Plan Width: 0
Actual Startup Time: 2.710
Actual Total Time: 2.710
Actual Rows: 51
Actual Loops: 1
Index Cond: "(upper((fullname)::text) ~~ 'DEVONSHIRE%'::text)"
Triggers:
Total Runtime: 2.883
Be case insensitive (with a varchar datatype), at the expense of making all your varchars in the database case insensitive.
Basics
Using PgAdmin PLPgSQL Debugger Intermediate
I'm one of those old-fashioned folks that debugs with print lines and raise notices. They're nice. They always work, you can put clock time stops in there and don't require any fancy configuration. At a certain point you do have to pull out a real debugger to see what is going on. This often happens when your one-liners are no longer good enough and now you have to write 20 liners of plpgsql code.
Such is the case with geocoding and the PostGIS tiger geocoder specifically. Lots of interest has revived on that with people submitting bug reports and we've got paying clients in need of a fairly easy and speedy drop-in geocoder that can be molded to handle such things as road way locations, badly mis-spelled real estate data, or just simply to get rid of their dependency on Google, Yahoo, MapQuest, ESRI and other online or pricey geocoding tools. So I thought I'd take this opportunity to supplement our old-fashioned debugging with plpgsqldebugger goodness. In this article, we'll show you how to configure the plpgsql debugger integrated in PgAdmin and run with it.
Installing and configuring the PgAdmin PL/PgSQL debugger
The pgAdmin plpgsql debugger has existed since PgAdmin 1.8 and PostgreSQL 8.3, so you need at least that version of PgAdmin and PostgreSQL to use it. You also need to run it under a super user account. So that unfortunately rules it out as an option for many use-cases. After all those conditions are met it takes a couple more steps to run with it. The libraries needed for it come prepackaged with EnterpriseDb packaged Windows/Linux/Mac OSX one click PostgreSQL installs and binaries. Not sure if it comes packaged with others or not. I tend to use it just in development mode so don't have installed on any of our production servers.
- Edit your server's postgresql.conf file in your data cluster and add the debugging shared library to your shared_preload_libraries. Make sure ot get rid of # remark if its present.:
shared_preload_libraries = '$libdir/plugins/plugin_debugger.dll'The profile one is optional. Note: the above is for windows server. If you are on Linux it would be:
shared_preload_libraries = '$libdir/plugins/plugin_debugger.so' - Install the file pldbgapi.sql in the database you want to debug plpgsql functions in. This is usually in the /share/contrib folder of your PostgreSQL install. You install it the same regardless of if you are on PostgreSQL 8.3-9.1.
- Restart your PostgreSQL server process.
Now we are ready to take the debugger for a test drive.
Using the plpgsql debugger
If you have installed the debugger correctly, when you open up PgAdmin III and navigate to the database you installed the debugger module and right-mouse click a plpgsql function, you should see a new Debug option with Debug and Set breakpoint sub-options as shown
 .
.- Choose the Debug option. This will allow you to type in arguments to the function. So for example for debugging my function of interest, my screen looks like this
after I click Debug and fill in my argument
 .
. - Once you've filled in the parameters, click the OK button, and you should get a screen that looks something like:
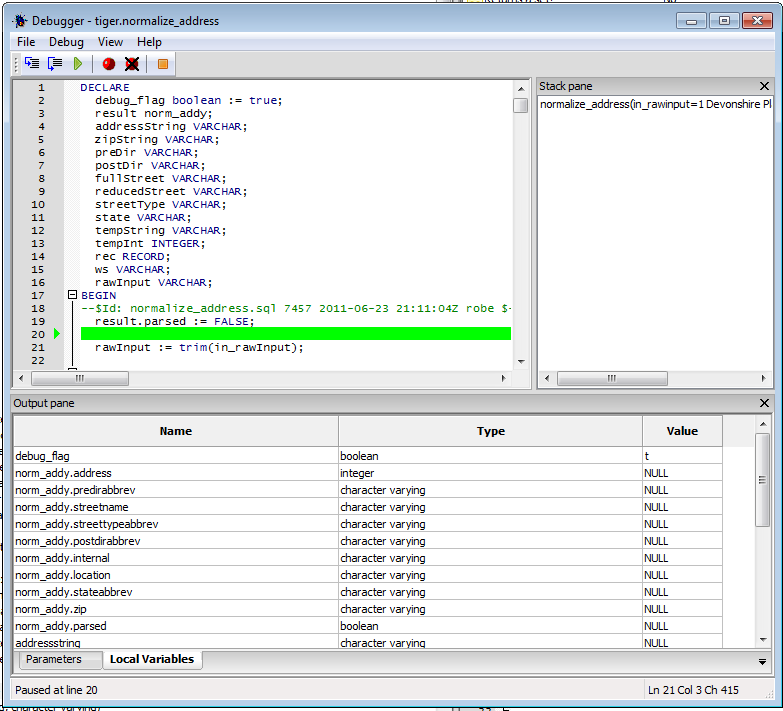
It's your basic debug with one panel showing the function code, allowing you to step thru and toggle breakpoints, a local variables panel showing you variables in function and highlighting when they change, a stack pane to monitor the calls, and a not too interesting Parameters pane to show you waht you type in for the function. It's a bit more interesting when you step thru other functions being called.
- Now we click the step into (F11) to see it in action.
A DBMS Messages output pane becomes visible too if you happen to have notices in your function.
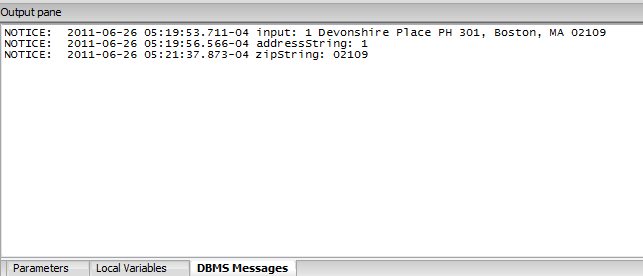
The Stack Pane shows what functions you are currently running, useful if your function calls other functions. If you do a step thru, you will also end up stepping into the other functions.

The Local Variables Pane changes as you step thru and the most recent change is marked in red:
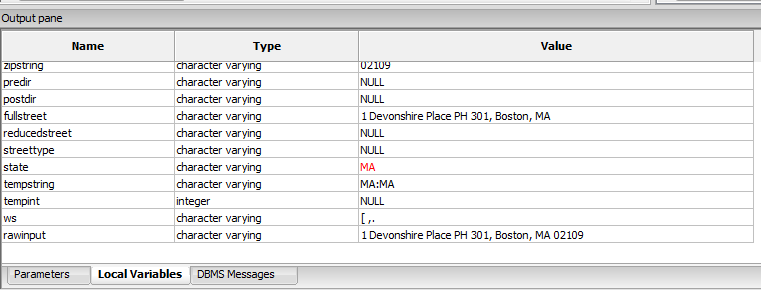
Once the function is done running, the Output Pane shows the result.

PL Programming
Variadic Functions in PostgreSQL Intermediate
PostgreSQL 8.4 introduced the ability to create user-defined variadic functions. These are basically functions that take as input an undefined number of arguments where the argument that is an undefined number are all of the same type and are the last input arguments. Depesz went over it two years ago in Waiting for 8.4 variadic functions, so we are a bit late to the party. In a nutshell -- variadic functions are syntactic sugar for functions that would otherwise take arrays. In this article we'll provide some more demonstrations of them to supplement Depesz article.
I was reminded that I had never explored this feature, when recently documenting one of the new PostGIS 2.0 Raster functions - ST_Reclass which employs this feature. I think ST_Reclass is a superb function and one of my favorite raster functions thus far that I hope to put to good use soon. Our new PostGIS family member,Bborie Park, is running thru our PostGIS Raster milestones much faster than I had dreamed. He's already implemented a good chunk of stuff we discussed in Chapter 13 - PostGIS Raster and had stated you probably won't see in PostGIS 2.0. He's going a bit faster than I can catalog them, so the documentation is already embarrassingly behind the fantastic functionality that is already present in PostGIS 2.0.
MySQL Concat() - Oh no!
I'm sure all MySQL lovers remember the MySQL concat function. You've probably even got some old code lying around that still uses it, despite the fact that MySQL now supports ANSI SQL || syntax if ANSI SQL is enabled. So what to do with this stuff if rewritting is not an option. Build an SQL Concat?
CREATE FUNCTION concat(VARIADIC param_args text[]) RETURNS text AS
$$
SELECT array_to_string($1,'');
$$
LANGUAGE 'sql';
SELECT concat('My ', 'dog ', 'likes ', 'chocolate') As result;
result
---------------------
My dog likes chocolate
PostGIS intersection taking an unspecified number of geometries
Someone asked this recently on PostGIS. I have always thought that PostGIS really needs an ST_Intersection aggregate function to compliment the ST_Union one. My needs for such a thing have been non-existent though. Just one of those fleeting fantasies that somewhere somebody needs an ST_Intersection aggregate function and/or a function that takes an indefinite number of geometries and intersects them. Then that someone came. So here is an example of the indefinite number of arguments. The aggregate version takes a few extra lines of code to write but is not that much more complicated.
CREATE OR REPLACE FUNCTION upgis_IntersectionMulti(VARIADIC param_geoms geometry[]) RETURNS geometry AS
$$
DECLARE result geometry := param_geoms[1];
BEGIN
-- an intersection with an empty geometry is an empty geometry
IF array_upper(param_geoms,1) > 1 AND NOT ST_IsEmpty(param_geoms[1]) THEN
FOR i IN 2 .. array_upper(param_geoms, 1) LOOP
result := ST_Intersection(result,param_geoms[i]);
IF ST_IsEmpty(result) THEN
EXIT;
END IF;
END LOOP;
END IF;
RETURN result;
END;
$$
LANGUAGE 'plpgsql';
SELECT ST_AsText(upgis_IntersectionMulti(ST_GeomFromText('LINESTRING(1 2, 3 5, 20 20, 10 11)'),
ST_Buffer(ST_Point(1,2), 10),
ST_GeomFromText('MULTIPOINT(1 2,3 6)'))) As result;
-- result --
POINT(1 2)
And of course for PostGIS 1.5+, the MultiUnion is a super trivial exercise.
-- Multi Union is even more trivial since
-- PostGIS has an ST_Union that takes an array of geometries
CREATE OR REPLACE FUNCTION upgis_UnionMulti(VARIADIC param_geoms geometry[])
RETURNS geometry AS
$$
SELECT ST_Union($1);
END;
$$
LANGUAGE 'sql';
SELECT ST_AsText(upgis_UnionMulti(ST_Buffer(ST_Point(5,5),10, 'quad_segs=1'),
ST_GeomFromText('LINESTRING(5 5, 5 10)') ,
ST_GeomFromText('POLYGON((1 2, 3 4, 2 2, 1 2))') )) As result;
result
--------
POLYGON((15 5,5.00000000000002 -5,-5 4.99999999999997,4.99999999999995 15,15 5))
Using PostgreSQL Extensions
PostgreSQL 9.1 Trigrams teaching LIKE and ILIKE new tricks Intermediate
There once existed programmers who were asked to explain this snippet of code: 1 + 2
- The C programmer explained "It's a common mathematical expression."
- The C++, Java, C# and other impure object-oriented programmers said "We concur. It's a common mathematical expression."
- The Smalltalk programmer explained "1 adds 2."
- The Lisp programmer stood up, a bit in disgust, and said, "No no! You are doing it all wrong!"
The Lisp Programmer then pulled out a Polish calculator, punched in+ 1 2,and with a very serious face, explained
"+ should be pushing those other two around."
I find this episode interesting because while the Lisp programmer I feel is more right, the Smalltalk programmer has managed to follow the rest of the crowd and still stick
to her core principle. This brings us to what does this have to do with trigrams
in PostgreSQL 9.1. Well just like 1 + 2 being a common mathematical expression, abc LIKE '%b%' is a common logical relational database expression that we have long taken for granted as not an indexable operation in most
databases (not any other database to I can think of) until PostgreSQL 9.1, which can utilize trigram indices (the Lisp programmer behind the curtain) to make it fast.
There are 2 main enhancements happening with trigrams in PostgreSQL 9.1 both of which depesz has already touched on in FASTER LIKE/ILIKE and KNNGIST. This means you can have an even faster trigram search than you ever have had before and you can do it in such a fashion that doesn't require any PostgreSQL trigram specific syntactical expressions. So while PostgreSQL 9.1 might be understanding LIKE much like all the other databases you work with, if you have a trigram index in place, it will just be doing it a little faster and sometimes a lot faster using the more clever PostgreSQL 9.1 planner. This is one example of how you can use applications designed for many databases and still be able to utilize advanced features in your database of choice. In this article we'll demonstrate.
For this example we'll use a table of 490,000 someodd records consisting of Massachusetts street segments and their names excerpted from TIGER 2010 data. You can download the trimmed data set from here if you want to play along.
The old story of using Btree Indexes
Normally if you plan to do LIKE searches, you would create a btree ops on the column or functional index on the upper/lower of the column. So here is the basic old in action:
CREATE INDEX idx_featnames_short_fullname_btree_ops
ON featnames_short USING btree (fullname varchar_pattern_ops);
vacuum analyze featnames_short;
-- takes 13ms returns 8 rows, uses btree ops index
SELECT DISTINCT fullname
FROM featnames_short
WHERE fullname LIKE 'Devonshire%';
EXPLAIN (ANALYZE true, FORMAT yaml)
SELECT DISTINCT fullname
FROM featnames_short
WHERE fullname LIKE 'Devonshire%';
- Plan:
Node Type: "Aggregate"
Strategy: "Hashed"
Startup Cost: 8.45
Total Cost: 8.47
Plan Rows: 2
Plan Width: 11
Actual Startup Time: 0.120
Actual Total Time: 0.121
Actual Rows: 8
Actual Loops: 1
Plans:
- Node Type: "Index Scan"
Parent Relationship: "Outer"
Scan Direction: "Forward"
Index Name: "idx_featnames_short_fullname_btree_ops"
Relation Name: "featnames_short"
Alias: "featnames_short"
Startup Cost: 0.00
Total Cost: 8.34
Plan Rows: 41
Plan Width: 11
Actual Startup Time: 0.024
Actual Total Time: 0.093
Actual Rows: 48
Actual Loops: 1
Index Cond: "(((fullname)::text ~>=~ 'Devonshire'::text) AND ((fullname)::text ~<~ 'Devonshirf'::text))"
Filter: "((fullname)::text ~~ 'Devonshire%'::text)"
Triggers:
Total Runtime: 0.161
-- takes 178ms returns 8 rows, uses no index
SELECT DISTINCT fullname
FROM featnames_short
WHERE fullname LIKE '%Devonshire%';
EXPLAIN (ANALYZE true, FORMAT yaml)
SELECT DISTINCT fullname
FROM featnames_short
WHERE fullname LIKE '%Devonshire%';
- Plan:
Node Type: "Aggregate"
Strategy: "Hashed"
Startup Cost: 9768.55
Total Cost: 9768.57
Plan Rows: 2
Plan Width: 11
Actual Startup Time: 125.773
Actual Total Time: 125.774
Actual Rows: 8
Actual Loops: 1
Plans:
- Node Type: "Seq Scan"
Parent Relationship: "Outer"
Relation Name: "featnames_short"
Alias: "featnames_short"
Startup Cost: 0.00
Total Cost: 9768.45
Plan Rows: 40
Plan Width: 11
Actual Startup Time: 24.995
Actual Total Time: 125.708
Actual Rows: 48
Actual Loops: 1
Filter: "((fullname)::text ~~ '%Devonshire%'::text)"
Triggers:
Total Runtime: 125.823-- takes 869 ms returns 8 rows uses no index
SELECT DISTINCT fullname
FROM featnames_short
WHERE fullname ILIKE '%Devonshire%';
EXPLAIN (ANALYZE true, FORMAT yaml)
SELECT DISTINCT fullname
FROM featnames_short
WHERE fullname ILIKE '%Devonshire%';
- Plan:
Node Type: "Aggregate"
Strategy: "Hashed"
Startup Cost: 9768.55
Total Cost: 9768.57
Plan Rows: 2
Plan Width: 11
Actual Startup Time: 842.275
Actual Total Time: 842.276
Actual Rows: 8
Actual Loops: 1
Plans:
- Node Type: "Seq Scan"
Parent Relationship: "Outer"
Relation Name: "featnames_short"
Alias: "featnames_short"
Startup Cost: 0.00
Total Cost: 9768.45
Plan Rows: 40
Plan Width: 11
Actual Startup Time: 113.184
Actual Total Time: 842.190
Actual Rows: 48
Actual Loops: 1
Filter: "((fullname)::text ~~* '%Devonshire%'::text)"
Triggers:
Total Runtime: 842.320
The new way
Well in the new way the btree is sometimes faster for some LIKE scenarios, but can't be employed in all where as the trigram works for all. In the new way we supplement our btree with a trigram index or use a trigram index instead to do most ILIKE searches and LIKE '%me%' like searches. Here is the same exercise repeated with adding on a trigram index.
-- Install trigram module if you don't have installed already
CREATE EXTENSION pg_trgm;
-- Add trigram index (seems to take much longer to build if have btree 28 secs))
CREATE INDEX idx_featnames_short_fullname_trgm_gist
ON featnames_short USING gist (fullname gist_trgm_ops);
vacuum analyze featnames_short;
-- repeat the exercise
--takes 13 ms returns 8 rows (uses btree like other)
SELECT DISTINCT fullname
FROM featnames_short
WHERE fullname LIKE 'Devonshire%';
EXPLAIN (ANALYZE true, FORMAT yaml)
SELECT DISTINCT fullname
FROM featnames_short
WHERE fullname LIKE 'Devonshire%';
- Plan:
Node Type: "Aggregate"
Strategy: "Hashed"
Startup Cost: 8.44
Total Cost: 8.46
Plan Rows: 2
Plan Width: 11
Actual Startup Time: 0.121
Actual Total Time: 0.123
Actual Rows: 8
Actual Loops: 1
Plans:
- Node Type: "Index Scan"
Parent Relationship: "Outer"
Scan Direction: "Forward"
Index Name: "idx_featnames_short_fullname_btree_ops"
Relation Name: "featnames_short"
Alias: "featnames_short"
Startup Cost: 0.00
Total Cost: 8.34
Plan Rows: 40
Plan Width: 11
Actual Startup Time: 0.024
Actual Total Time: 0.092
Actual Rows: 48
Actual Loops: 1
Index Cond: "(((fullname)::text ~>=~ 'Devonshire'::text) AND ((fullname)::text ~<~ 'Devonshirf'::text))"
Filter: "((fullname)::text ~~ 'Devonshire%'::text)"
Triggers:
Total Runtime: 0.167
--takes 13 ms returns 8 rows - uses gist
SELECT DISTINCT fullname
FROM featnames_short
WHERE fullname ILIKE 'Devonshire%';
EXPLAIN (ANALYZE true, FORMAT yaml)
SELECT DISTINCT fullname
FROM featnames_short
WHERE fullname ILIKE 'Devonshire%';
- Plan:
Node Type: "Aggregate"
Strategy: "Hashed"
Startup Cost: 152.77
Total Cost: 152.79
Plan Rows: 2
Plan Width: 11
Actual Startup Time: 3.647
Actual Total Time: 3.649
Actual Rows: 8
Actual Loops: 1
Plans:
- Node Type: "Bitmap Heap Scan"
Parent Relationship: "Outer"
Relation Name: "featnames_short"
Alias: "featnames_short"
Startup Cost: 4.76
Total Cost: 152.67
Plan Rows: 40
Plan Width: 11
Actual Startup Time: 3.403
Actual Total Time: 3.613
Actual Rows: 48
Actual Loops: 1
Recheck Cond: "((fullname)::text ~~* 'Devonshire%'::text)"
Plans:
- Node Type: "Bitmap Index Scan"
Parent Relationship: "Outer"
Index Name: "idx_featnames_short_fullname_trgm_gist"
Startup Cost: 0.00
Total Cost: 4.75
Plan Rows: 40
Plan Width: 0
Actual Startup Time: 3.378
Actual Total Time: 3.378
Actual Rows: 48
Actual Loops: 1
Index Cond: "((fullname)::text ~~* 'Devonshire%'::text)"
Triggers:
Total Runtime: 3.720
-- takes 14-18 ms returns 8 rows uses gist bitmap index scan with heap scan
SELECT DISTINCT fullname
FROM featnames_short
WHERE fullname ILIKE '%Devonshire%';
EXPLAIN (ANALYZE true, FORMAT yaml)
SELECT DISTINCT fullname
FROM featnames_short
WHERE fullname ILIKE '%Devonshire%';
- Plan:
Node Type: "Aggregate"
Strategy: "Hashed"
Startup Cost: 152.77
Total Cost: 152.79
Plan Rows: 2
Plan Width: 11
Actual Startup Time: 5.586
Actual Total Time: 5.588
Actual Rows: 8
Actual Loops: 1
Plans:
- Node Type: "Bitmap Heap Scan"
Parent Relationship: "Outer"
Relation Name: "featnames_short"
Alias: "featnames_short"
Startup Cost: 4.76
Total Cost: 152.67
Plan Rows: 40
Plan Width: 11
Actual Startup Time: 5.351
Actual Total Time: 5.553
Actual Rows: 48
Actual Loops: 1
Recheck Cond: "((fullname)::text ~~* '%Devonshire%'::text)"
Plans:
- Node Type: "Bitmap Index Scan"
Parent Relationship: "Outer"
Index Name: "idx_featnames_short_fullname_trgm_gist"
Startup Cost: 0.00
Total Cost: 4.75
Plan Rows: 40
Plan Width: 0
Actual Startup Time: 5.325
Actual Total Time: 5.325
Actual Rows: 48
Actual Loops: 1
Index Cond: "((fullname)::text ~~* '%Devonshire%'::text)"
Triggers:
Total Runtime: 5.655
Some old rules still apply
If your queries are writtern something like below then the below query will not use an index:
-- This will not use an index --
SELECT fullname
FROM featnames_short
WHERE upper(fullname) LIKE '%DEVONSHIRE%';
There is no index above that will work for this, however if you put in an index on:
-- But if you do this the above uses an index again (14 ms - 8 rows)--
CREATE INDEX idx_featnames_short_ufullname_trgm_gist
ON featnames_short USING gist (upper(fullname) gist_trgm_ops);
What about citext and case insensitive LIKE found in MySQL and SQL Server
Sadly, we couldn't figure out how to get citext to use an index regardless of what we did. Though the hack we described a while ago of turning your PostgreSQL varchar() columns into case insensitive columns and putting a trigram gist index on upper(fullname) seems to work just dandy.
--finishes in 13-17ms and returns 9 rows
--(using CASE INSENSITIVE OPERATORS HACK for varchar columns) --
SELECT DISTINCT fullname FROM featnames_short WHERE fullname LIKE '%devonshire%';
- Plan:
Node Type: "Aggregate"
Strategy: "Hashed"
Startup Cost: 4113.74
Total Cost: 4114.62
Plan Rows: 88
Plan Width: 12
Actual Startup Time: 2.848
Actual Total Time: 2.850
Actual Rows: 9
Actual Loops: 1
Plans:
- Node Type: "Bitmap Heap Scan"
Parent Relationship: "Outer"
Relation Name: "featnames_short"
Alias: "featnames_short"
Startup Cost: 138.38
Total Cost: 4106.67
Plan Rows: 2825
Plan Width: 12
Actual Startup Time: 2.725
Actual Total Time: 2.826
Actual Rows: 51
Actual Loops: 1
Recheck Cond: "(upper((fullname)::text) ~~ 'DEVONSHIRE%'::text)"
Plans:
- Node Type: "Bitmap Index Scan"
Parent Relationship: "Outer"
Index Name: "idx_featnames_short_ufullname_trgm_gist"
Startup Cost: 0.00
Total Cost: 137.67
Plan Rows: 2825
Plan Width: 0
Actual Startup Time: 2.710
Actual Total Time: 2.710
Actual Rows: 51
Actual Loops: 1
Index Cond: "(upper((fullname)::text) ~~ 'DEVONSHIRE%'::text)"
Triggers:
Total Runtime: 2.883
Be case insensitive (with a varchar datatype), at the expense of making all your varchars in the database case insensitive.