

 PostGIS in Action
About the Authors
Consulting
PostGIS in Action
About the Authors
Consulting
Thursday, December 27. 2007CrossTab Queries in PostgreSQL using tablefunc contribPrinter FriendlyRecommended Books: PostgreSQL 8.4 Internals and Appendixes (contribs) SQL Queries for Mere Mortals SQL Visual Quick Start The generic way of doing cross tabs (sometimes called PIVOT queries) in an ANSI-SQL database such as PostgreSQL is to use CASE statements which we have documented in the article What is a crosstab query and how do you create one using a relational database?. In this particular issue, we will introduce creating crosstab queries using PostgreSQL tablefunc contrib. Installing TablefuncTablefunc is a contrib that comes packaged with all PostgreSQL installations - we believe from versions 7.4.1 up (possibly earlier). We will be assuming the one that comes with 8.2 for this exercise. Note in prior versions, tablefunc was not documented in the standard postgresql docs, but the new 8.3 seems to have it documented at http://www.postgresql.org/docs/8.3/static/tablefunc.html. Often when you create crosstab queries, you do it in conjunction with GROUP BY and so forth. While the astute reader may conclude this from the docs, none of the examples in the docs specifically demonstrate that and the more useful example of crosstab(source_sql,category_sql) is left till the end of the documentation. To install tablefunc simply open up the share\contrib\tablefunc.sql in pgadmin and run the sql file. Keep in mind that the functions are installed by default in the public schema.
If you want to install in a different schema - change the first line that reads Alternatively you can use psql to install tablefunc using something like the following command: We will be covering the following functions
There are a couple of key points to keep in mind which apply to both crosstab functions.
Setting up our test dataFor our test data, we will be using our familiar inventory, inventory flow example. Code to generate structure and test data is shown below.
Using crosstab(source_sql, category_sql)For this example we want to show the monthly usage of each inventory item for the year 2007 regardless of project. The crosstab we wish to achieve would have columns as follows: item_name, jan, feb, mar, apr, may, jun, jul, aug, sep, oct, nov, dec
--Resulting crosstab query
--Note: For this we don't need the order by month since the order of the columns is determined by the category_sql row order
The output of the above crosstab looks as follows: Using crosstab(source_sql)crosstab(source_sql) is much trickier to understand and use than the crosstab(source_sql, category_sql) variant, but in certain situations and certain cases is faster and just as effective. The reason why is that crosstab(source_sql) is not guaranteed to put same named buckets in the same columns especially for sparsely populated data. For example - lets say you have data for CSCL for Jan Mar Apr and data for Phenol for Apr. Then Phenols Apr bucket will be in the same column as CSCL Jan's bucket. This in most cases is not terribly useful and is confusing. To skirt around this inconvenience one can write an SQL statement that guarantees you have a row for each permutation of Item, Month by doing a cross join. Below is the above written so item month usage fall in the appropriate buckets.
In actuality the above query if you have an index on action_date is probably more efficient for larger datasets than the crosstab(source, category) example since it utilizes a date range condition for each month match. There are a couple of situations that come to mind where the standard behavior of crosstab of not putting like items in same column is useful. One example is when its not necessary to distiguish bucket names, but order of cell buckets is important such as when doing column rank reports. For example if you wanted to know for each item, which projects has it been used most in and you want the column order of projects to be based on highest usage. You would have simple labels like item_name, project_rank_1, project_rank_2, project_rank_3 and the actual project names would be displayed in project_rank_1, project_rank_2, project_rank_3 columns.
Output of the above looks like: Tricking crosstab to give you more than one row header columnRecall we said that crosstab requires exactly 3 columns output in the sql source statement. No more and No less. So what do you do when you want your month crosstab by Item, Project, and months columns. One approach is to stuff more than one Item in the item slot by either using a delimeter or using an Array. We shall show the array approach below.
Result of the above looks as follows: 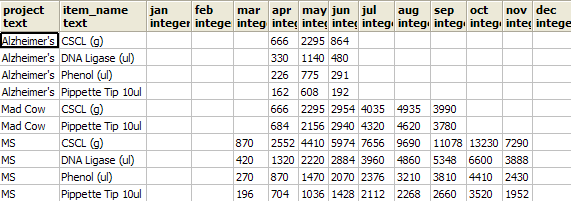
Building your own custom crosstab functionIf month tabulations are something you do often, you will quickly become tired of writing out all the months. One way to get around this inconvenience - is to define a type and crosstab alias that returns the well-defined type something like below:
Then you can write the above query as
Adding a Total column to the crosstab queryAdding a total column to a crosstab query using crosstab function is a bit tricky. Recall we said the source sql should have exactly
3 columns (row header, bucket, bucketvalue). Well that wasn't entirely accurate. The crosstab(source_sql, category_sql) variant of the function
allows for a source that has columns row_header, extraneous columns, bucket, bucketvalue.
Don't get extraneous columns confused with row headers. They are not the same and if you try to use it as we did for creating multi row columns, you will
be leaving out data. For simplicity here is a fast rule to remember.
Resulting output of our cross tabulation with total column looks like this: 
If per chance you wanted to have a total row as well you could do it with a union query in your source sql. Unfotunately PostgreSQL does not support windowing functions that would make the row total not require a union. We'll leave that one as an exercise to figure out. Another not so obvious observation. You can define a type that say returns 20 bucket columns, but your actual crosstab need not return up to 20 buckets. It can return less and whatever buckets that are not specified will be left blank. With that in mind, you can create a generic type that returns generic names and then in your application code - set the heading based on the category source. Also if you have fewer buckets in your type definition than what is returned, the right most buckets are just left off. This allows you to do things like list the top 5 colors of a garment etc. Comments
Display comments as
(Linear | Threaded)
This is nice, but as I see it always presumes that you know your data before you do the crosstab. Even if you specify your columns with an sql statement you still need to enumerate all resulting columns individually in the As mthreport(...) part.
I have searched extensively but could not find a plpgsql based solution for the situation where you don't know what the categories will be. If you have any solution for that please let me know. Thx. SWK
Good question. Sadly I don't think there is an easy answer. To get around the issue say in PHP and so forth, we use dummy names in our sql statement or a dummy type with lots of output columns and then in PHP to display the header, loop thru our category sql recordset.
The problem is not so much with crosstab as with PostgreSQL inability to deal with dynamic record types or ability to do record introspection. This has been discussed as a future enhancement for example here http://archives.postgresql.org/pgsql-patches/2005-07/msg00458.php But unfortunately haven't heard any recent talk of it.
I'm pretty new in RDBMS and in PostGreSQL, and I recently discovered crosstab utility so maybe I'm wrong but, as you say "I have searched extensively but could not find a plpgsql based solution for the situation where you don't know what the categories will be", did you have a look at
http://www.ledscripts.com/tech/article/view/5.html ? I am also looking for a solution for dynamical categories... Cheers, -- Denis
Hi, can you help me please!
I need create sql that returns fils an no colums. There is some function similar to PIVOT of ORACLE for EnterpriseDB? For example I want a structrue this paciente vacuna1 vacuna2 vacunaN jhon 01/01/08 01/02/08 01/03/08 daniel 03/01/08 03/02/08 03/03/08 but sql returns this: paciente vacuna1 vacuna2 vacunaN jhon 01/01/08 jhon 01/02/08 jhon 01/03/08 daniel 03/01/08 daniel 03/02/08 daniel 03/03/08 I'm from El Salvador. thank, wake up your help!
Hello,
I've been looking for such a "generic" crosstab for monthes. Does anyone know whether there were recent progress, on this point? Cheers. And happy new year! A+ Pierre
Maybe you could dynamically write the crosstab query in a plpgsql procedure.
You would first query your data to get the categories, write the record types string, then write the query itself ?
Thank you for the great howto to crosstab functionality. However, I am not able to follow your last hint about having a type with more buckets than the crosstab function returns.
For example, I create the following type and method: CREATE TYPE tablefunc_crosstab_year AS (row_name text,jan integer, feb integer, mar integer, apr integer, may integer, jun integer, jul integer, aug integer, sep integer, oct integer, nov integer, dec integer, jan1 integer); CREATE OR REPLACE FUNCTION crosstabyear(text, text) RETURNS SETOF tablefunc_crosstab_year AS '$libdir/tablefunc', 'crosstab_hash' LANGUAGE 'c' STABLE STRICT; and when I call the function like this SELECT mthreport.* FROM crosstabyear('SELECT if.project::text As row_name, to_char(if.action_date, ''mon'')::text As bucket, SUM(if.num_used)::integer As bucketvalue FROM inventory As i INNER JOIN inventory_flow As if ON i.item_id = if.item_id AND action_date BETWEEN date ''2007-01-01'' and date ''2007-12-31 23:59'' WHERE if.num_used 0 GROUP BY if.project, to_char(if.action_date, ''mon''), date_part(''month'', if.action_date) ORDER BY if.project', 'SELECT to_char(date ''2007-01-01'' + (n || '' month'')::interval, ''mon'') As short_mname FROM generate_series(0,11) n') As mthreport; I get the error: ERROR: invalid return type DETAIL: Query-specified return tuple has 14 columns but crosstab returns 13. Could you give me some pointer what I'm doing wrong here? Thanks a lot, Andreas
Andreas,
Could be a postgresql version issue. Which version of PostgreSQL are you using? Just tried your example and it worked for me under 8.3 and a beta version of 8.4. Don't have 8.2 and lower lying around. The only thing is that your query seems to be missing an = sign -- but that would have generated a different error or got stripped for some reason by the commenter. So the query I tried is SELECT mthreport.* FROM crosstabyear('SELECT if.project::text As row_name, to_char(if.action_date, ''mon'')::text As bucket, SUM(if.num_used)::integer As bucketvalue FROM inventory As i INNER JOIN inventory_flow As if ON i.item_id = if.item_id AND action_date BETWEEN date ''2007-01-01'' and date ''2007-12-31 23:59'' WHERE if.num_used = 0 GROUP BY if.project, to_char(if.action_date, ''mon''), date_part(''month'', if.action_date) ORDER BY if.project', 'SELECT to_char(date ''2007-01-01'' + (n || '' month'')::interval, ''mon'') As short_mname FROM generate_series(0,11) n') As mthreport;
Hello Regina,
thanks for your answer. I am using a vanilla installation of postgres 8.3 on Ubuntu 8.10. Actually, my query missed the not equal '!=' sign. If I write the line in question like WHERE if.num_used != 0 I get my stated Error. If the result of the query is empty (which happens if you use the equal sign), there is no error, but that is not what I want. Andreas
Andreas,
Okay I get the same error you do so I guess I was wrong that this was possible. I'll have to investigate and see if there is a work-around for this issue.
Thanks for write-up. How about just converting a set of rows into a comma-separted column value. you can do something like this in SQLServer/Oracle with XML but it doesn't seem to be usable as within a subquery and has XML element gunk embedded there too. Just somethign simple so one could take a list of rows and create a comma separated value to insert elsewhere. I know you know the db is snafu but it is what it is and crapola db design is part of the course when you work in Fortunate 500.
I have a peculiar need, perhaps somebody may have already answered this.
I need a cross tab that can change the categories dynamically. Thanks in advance for your help |
Entry's LinksQuicksearchCalendar
Categories
ArchivesSubscribeBlog Administration |
|||||||||||||||||||||||||||||||||||||||||||||||||



Tracked: May 20, 04:13
Tracked: Jan 04, 15:05